本文主要通过以下几个方面来系统的介绍 RabbitMQ 框架:
参考资料
一、MQ 的基本概念
1 MQ 的概述
MQ 全称 Message Queue(消息队列),是在消息的传输过程中保存的容器。多用于分布式系统之间进行通信。
下图是两种分布式的数据通信方式:
- 直接通信(耦合)
graph subgraph 直接调用 a[A系统] --"远程调用"--> b[B系统] end
- 间接通信(解耦合)
graph LR subgraph 消息生产者 a[A 系统] end subgraph 中间件 MQ[(MQ 消息队列)] end subgraph 消息消费者 b[B 系统] end a ---> MQ ---> b
2 MQ 的优劣势
【MQ 的优势】
-
应用解耦:提升容错性和可维护性。
graph LR p[顾客] a[订单系统] b[库存系统] c[支付系统] d[物流系统] x[其他新加入的系统] subgraph 中间件 MQ[(MQ 消息队列)] end p --> a a --> MQ MQ --"❌"--> b MQ --> c MQ --> d MQ -.-> x
-
在如上所示的这个系统中,如果“订单系统”与“库存系统”等子系统直接联系,那么当任意一个子系统(如“库存系统”)出错时,“订单系统”会因为无法得到正确的返回而出错。
-
如果我们引入消息队列之后,“订单系统”向消息队列发送消息后成功返回,然后各个子系统在从消息队列中“取出”属于自己的消息进行消费。这样就将“订单系统”与各个子系统解耦开了,即使子系统出错,其他系统也不会接连出错。
如果有其他子系统接入,那么也只需要和 MQ 对接即可。
-
-
异步提速:
graph LR p[顾客] a[订单系统] b[库存系统 300ms] c[支付系统 300ms] d[物流系统 300ms] db[(数据库)] subgraph 中间件 MQ[MQ 消息队列] end p --> a a --"5 ms"--> MQ a --"20 ms"--> db MQ --"5 ms"--> b MQ --"5 ms"--> c MQ --"5 ms"--> d
我们同样以上个系统为例,此时我们考虑其运行速度:
-
如果没有 MQ,那么订单系统要等待所有的子系统处理完成后才能返回,那么总时长就是
-
如果有 MQ,订单系统将消息发送到 MQ 之后就可以成功返回,总时长 。
思考 💡
这里我们可以看到,“订单系统”将消息发送到 MQ 之后就成功返回,并没有考虑后续消费消息的子系统是否成功消费了该消息。那么如果子系统出错了,该怎么使得“订单系统”知道呢?
-
-
削峰填谷:MQ 可以作为一个请求的“蓄水池”,如果短时间内接受到大量请求,可以将这些请求存储在 MQ 中(削峰),再逐步消费(填谷)。
graph LR subgraph 大量请求 r1[请求1] r2[请求2] r3[请求3] rn[请求n] end mq[消息队列] a[A 系统] db[数据库] r1 --> mq r2 --> mq r3 --> mq rn --> mq mq --"100req/s"--> a a --> db
【MQ 的劣势】
- 系统的可用性降低:系统引入的外部以来越多,系统的稳定性就越低。一旦 MQ 宕机,就会对业务产生影响。那么如何保证 MQ 的高可用呢?
- 系统复杂度提高:MQ 的引入大大的提升了系统的复杂度。之前的系统间是同步的远程调用,现在是通过 MQ 进行异步调用。如何保证消息没有被重复消费(幂等性)?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?
- 一致性问题:当 A 系统处理完业务,通过 MQ 向 B、C、D 三个系统发送消息数据,如果 B 系统、C 系统处理成功,D 系统处理失败,那么系统间的数据就不一致了。如何保证消息处理的一致性?
【使用场景】
我们在了解了 MQ 的优劣势后,使用 MQ 需要满足哪些条件呢?
- 生产者不需要从消费者处获得反馈。引入消息队列之前的直接调用,其接口的返回值应该为空,即所谓满足异步调用的要求。
- 容许短暂的不一致性。
- 解耦、提速、削峰这些方面的收益,超过加入 MQ,管理 MQ 的成本。
3 常见的 MQ 产品
目前业界有很多的 MQ 产品,例如 RabbitMQ、RocketMQ、ActiveMQ、Kafka、 ZeroMQ、 MetaMQ 等,也有直接使用 Redis 充当 MQ 的案例。而这些消息队列产品,各有侧重,在实际选型时需要结合自身需求及 MQ 产品特征,综合考虑。
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | Alibaba | Apache |
| 开发语言 | Erlang | Java | Java | Scala & Java |
| 协议支持 | AMQP、XMPP、SMTP、STOMP | OpenWire、STOMP、REST、XMPP、AMQP | 自定义 | 自定义协议,社区封装了 http 协议支持 |
| 客户端支持语言 | 官方支持 Erlang、Java、Ruby 等,社区产出多种 API,几乎支持所有语言 | Java、C、C++、Python、PHP、Perl、.net 等 | Java、C++(并不成熟) | 官方支持 Java,社区产出多种 API |
| 单机吞吐量 | 万级 | 万级 | 十万级 | 十万级 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 功能特性 | 并发能力强,性能极好,延时低,社区活跃,管理界面丰富 | 老牌产品,成熟度高,文档较多 | MQ 功能比较完善,扩展性佳 | 只支持主要的 MQ 功能,主要面向大数据领域 |
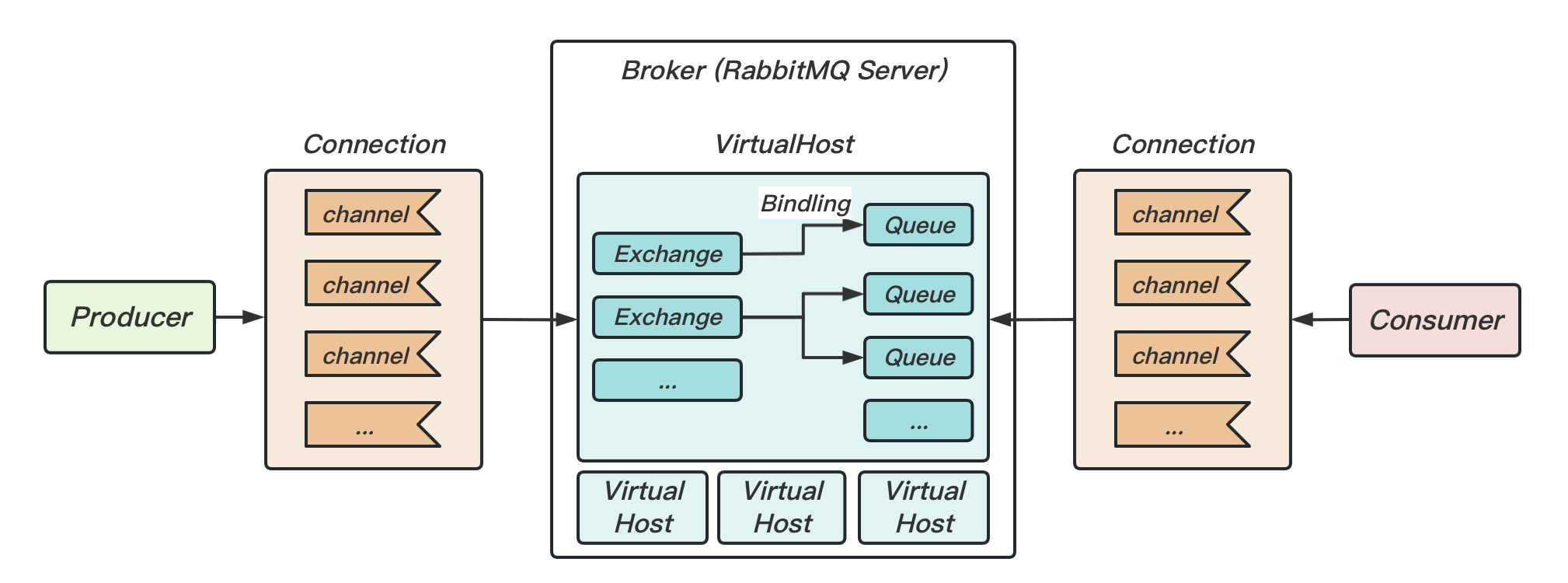
4 RabbitMQ 简介
我们在之前介绍 RabbitMQ 支持协议时,提及了 AMQP。
AMQP,即 Advanced Message Queue Protocol(高级消息队列协议),是一个网络协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品、不同开发语言等条件的限制。类比于 HTTP 协议。
在 AMQP 协议中,规定了如下角色:
graph LR p[Publisher] c[Consumer] subgraph MQ e[Exchange] q[Queue] end p --"Publishes"--> e e --"Routes"--> q q --"Consumes"--> c
- 首先由消息的发布者(Publisher)将消息发布(Publishes)到 MQ 中;
- MQ 中存在一个“交换机”(Exchange),用来把消息路由到(Routes)目标的队列(Queue)中;
- 最后由消息的消费者(Consumer)监听这个队列,从队列中消费(Consumes)消息。