写在前面:
本文章是根据法国国立高等电力技术、电子学、计算机、水力学与电信学校 (E.N.S.E.E.I.H.T.) 第九学期课程 “Infrastructure for Big Data” 及以下参考资料总结而来的课程笔记。碍于本人学识有限,部分叙述难免存在纰漏,请读者注意甄别。
参考资料:
- S. Ghemawat, H. Gobioff, S. Leung, The Google File System, Google Inc., 2003
- J. Dean and S. Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, Google Inc., 2004
- F. Chang, J. Dean, S. Ghemawat, Bigtable: A Distributed Storage System for Structured Data, Google Inc., 2006
1. Hadoop
1.1 Hadoop 入门概念
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,其理论模型来自于 Google 的三篇论文:
- S. Ghemawat, H. Gobioff, S. Leung, The Google File System, 2003
- J. Dean and S. Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, 2004
- F. Chang, J. Dean, S. Ghemawat, Bigtable: A Distributed Storage System for Structured Data, 2006
主要解决:海量数据的存储和分析计算问题
广义上来说,Hadoop 通常是指一个更加广泛的概念:Hadoop 生态圈。
Hadoop 优势:
- 高可靠性:Hadoop 底层维护多个数据副本(默认为3个副本),当某个 Hadoop 计算或存储单元出现故障,也不会导致数据的丢失;
- 高扩展性:在集群间分配任务数据,可以方便地动态扩展数以千计的节点;
- 高效性:在 Map-Reduce 的思想下,Hadoop 是并行工作的,以加快任务的处理速度;
- 高容错性:可以自动将失败的任务自动分配。
Hadoop 的组成
Hadoop 1.x 和 2.0 的组成
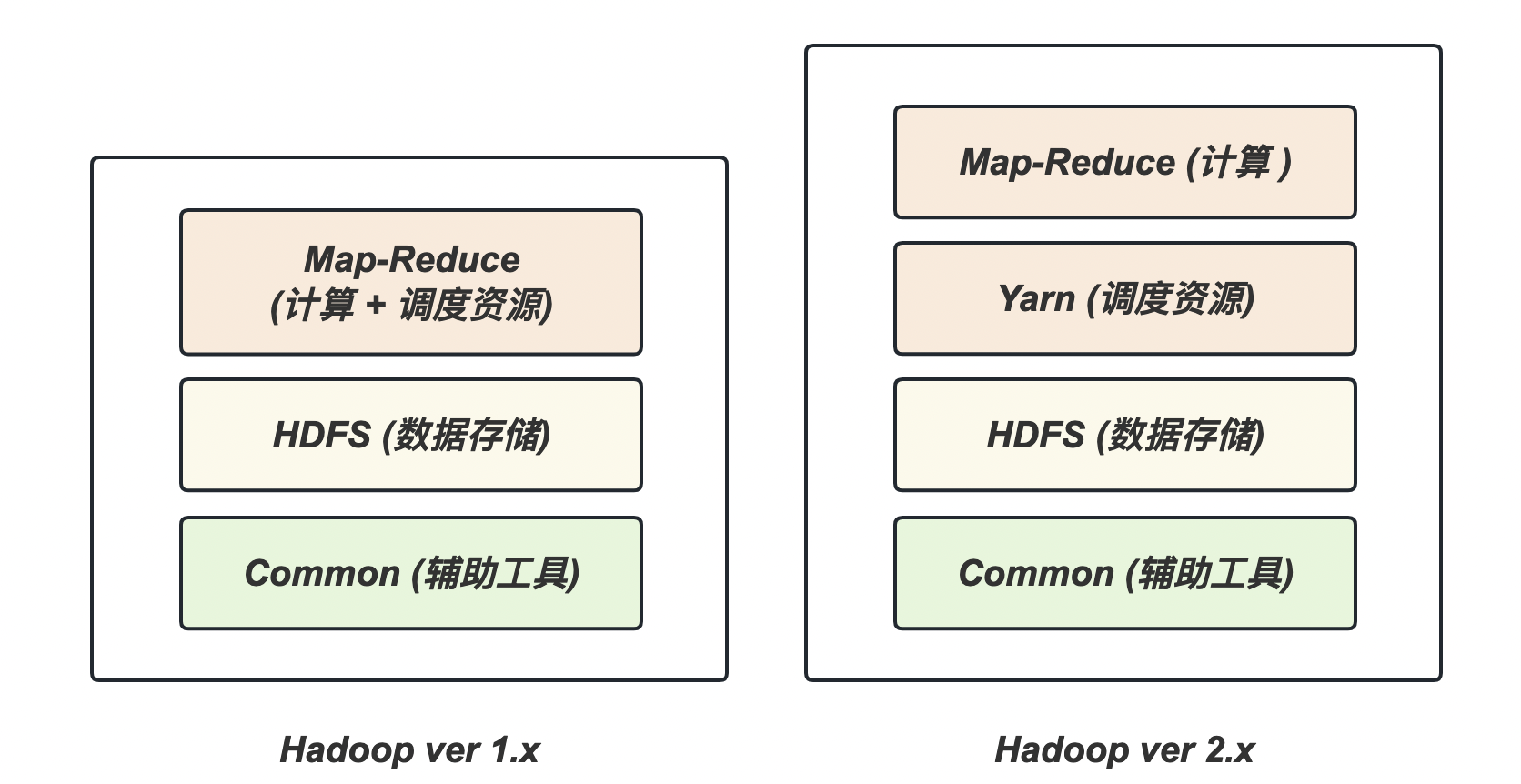
- 在 Hadoop
1.x的时代,Hadoop 中的 Map-Reduce 同时处理业务逻辑运算和资源调度,耦合性较大; - 在 Hadoop
2.x的时代,增加了 Yarn 来负责资源的调度
HDFS 架构概述
Hadoop Distributed File System,简称 HDFS, 是一个分布式文件系统。其主要结构如下:
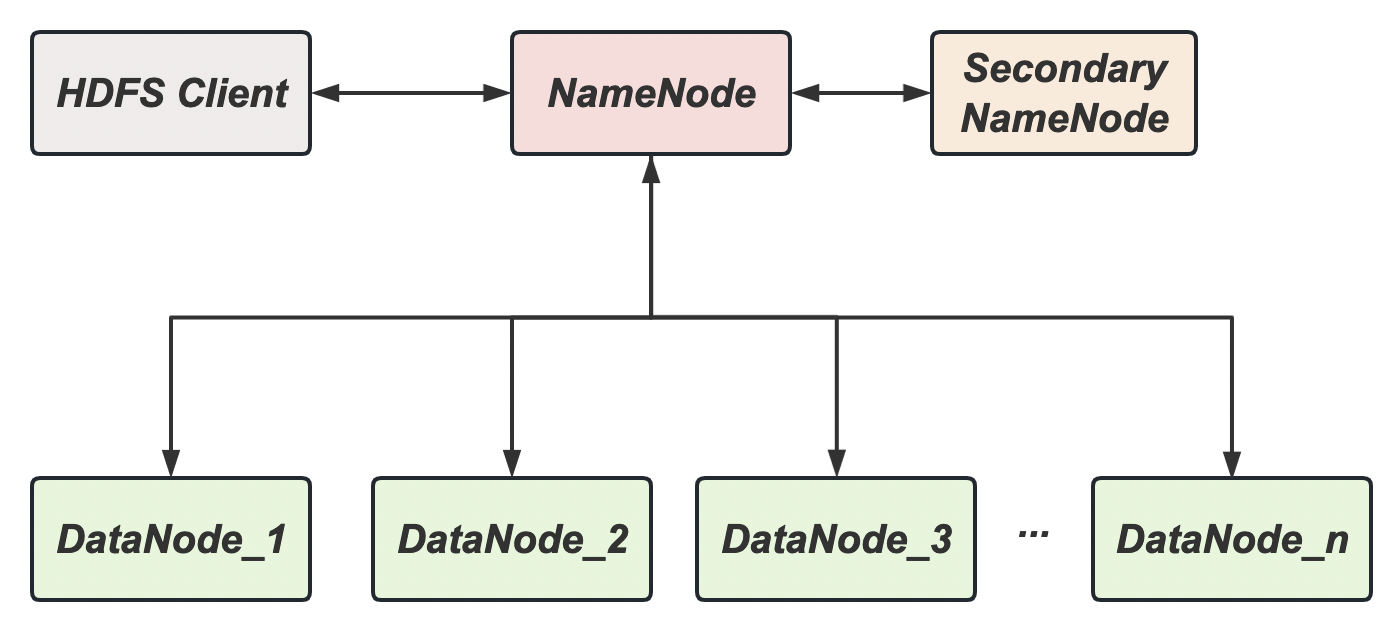
- NameNode:存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限等),以及每个文件的块(block)列表和块所在的 DataNode 等
- Secondary NameNode:是对 NameNode 元数据的部分备份,当 NameNode 无法工作时,其会恢复部分数据
- DataNode:在本地文件系统存储数据块数据,以及块数据的校验和
YARN 结构概述
Yet Another Resource Negotiator,简称 YARN,是另一种资源协调者,是 Hadoop 的资源管理器(主要管理 CPU 和内存)。其主要结构如下:
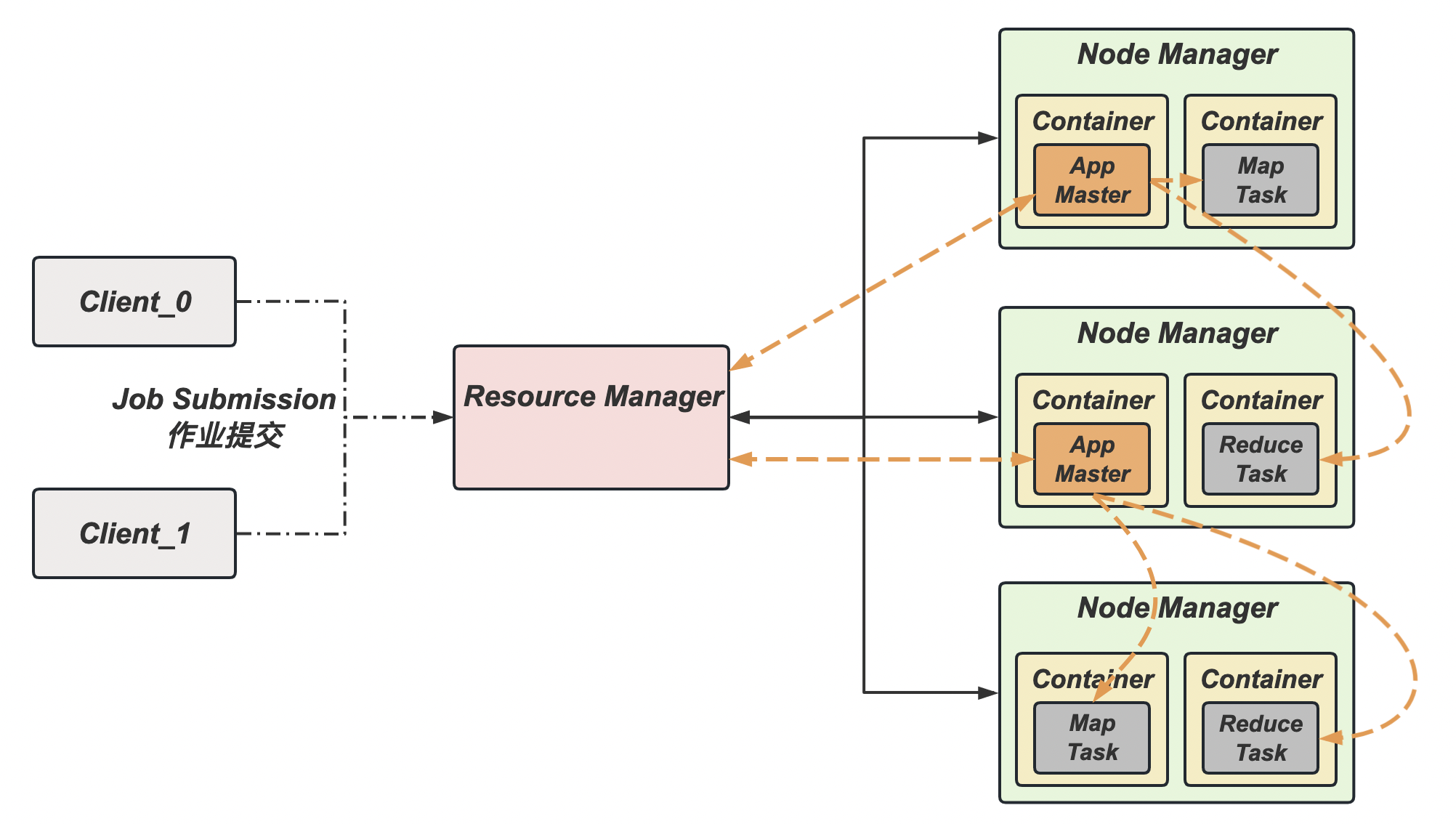
- Resource Manager:整个集群资源(内存、CPU)的管理者;
- Node Manager:单个节点服务器的资源管理者;
- Container:容器概念,封装了任务运行时所需的资源,如内存、CPU、磁盘、网络等;
- Application Master:单个任务运行的资源管理者,一个集群上可以运行多个AppMaster
- Client:客户端接口,同一个集群可以支持多客户端访问
Map-Reduce 架构概述
Map-Reduce 将计算过程分为两个阶段:Map 阶段和 Reduce 阶段。
- Map 阶段:进行并行处理输入数据;
- Reduce 阶段:对 Map 的结果进行汇总。
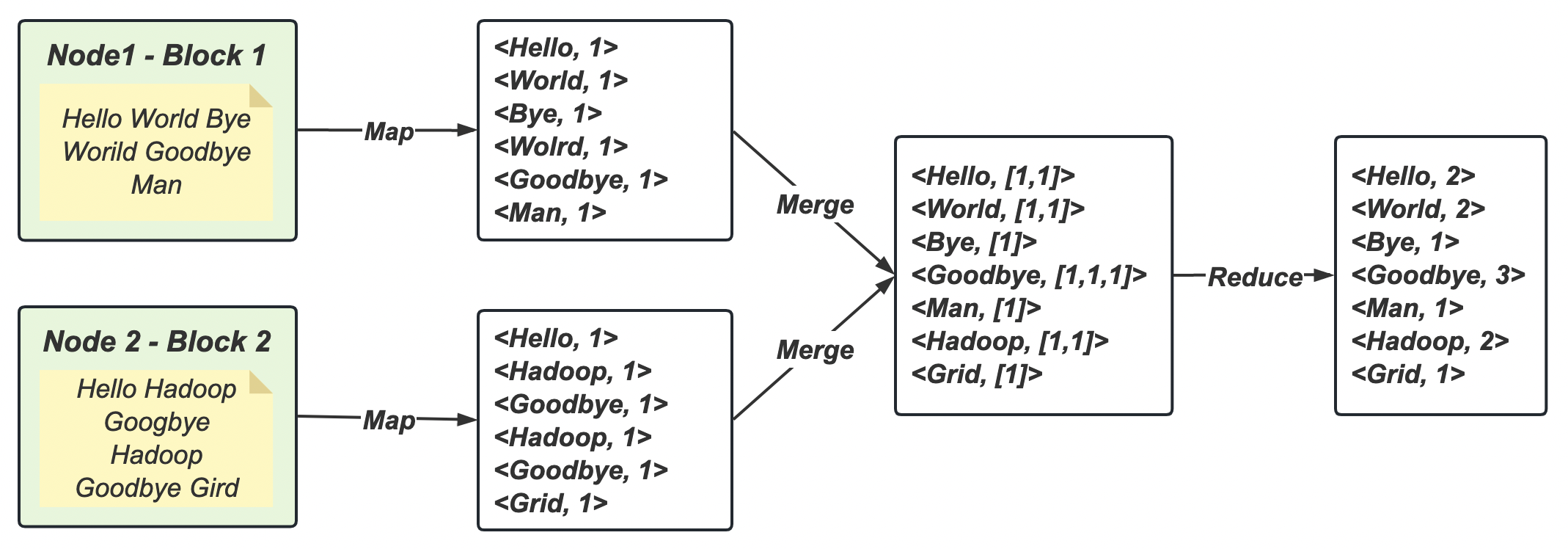
HDFS、YARN、MapReduce 三者关系
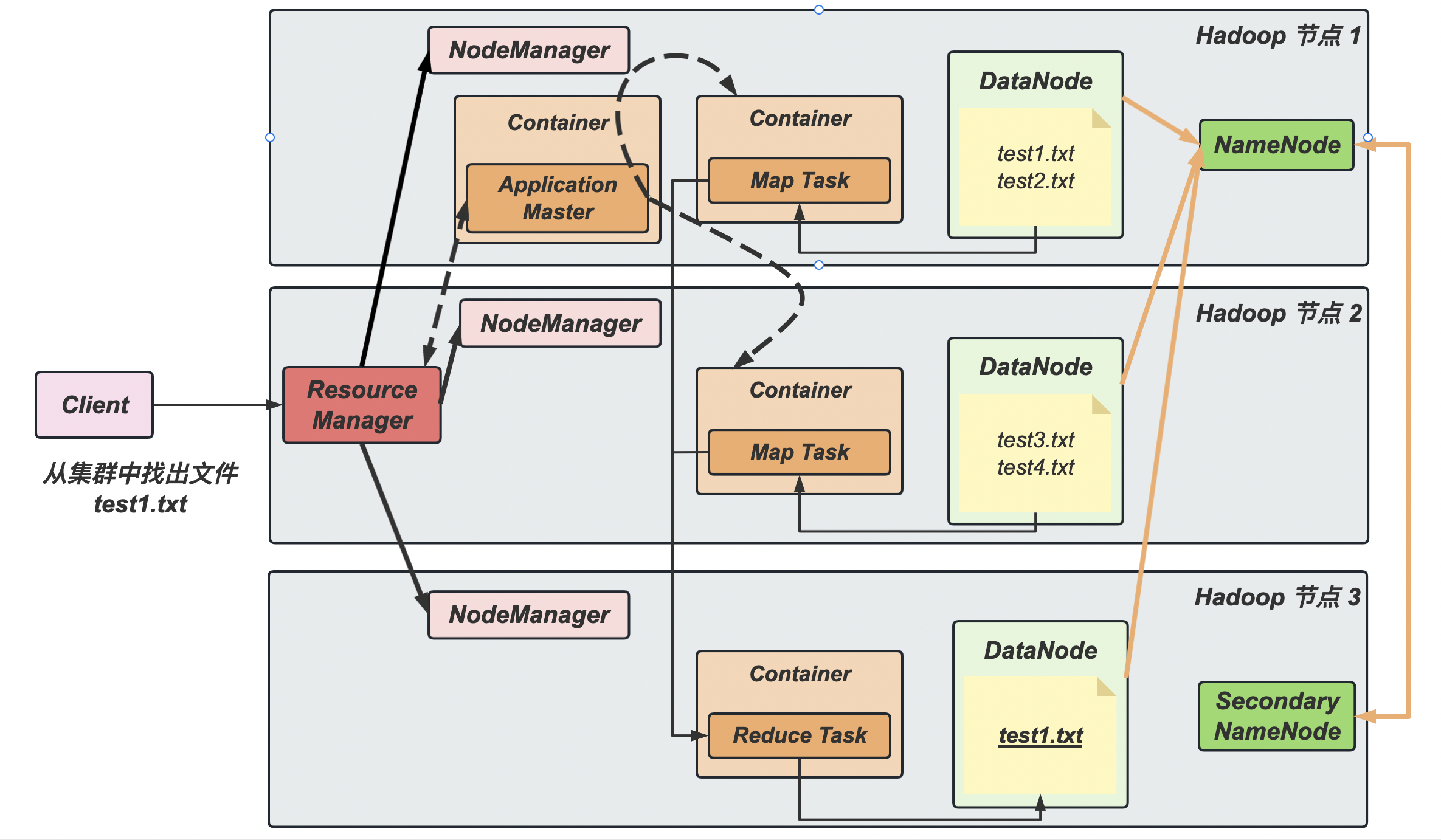
在上图中,绿色系代表HDFS 结构,红色系代表 YARN 结构,橙色系代表 Map-Reduce 结构
1.2 HDFS
HDFS 概述
HDFS 产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
HDFS 定义
HDFS (Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS 优缺点
【优点】
- 高容错性:数据自动保存多个副本,某个副本丢失后,可以自动恢复。
- 适合处理大数据:包括单体大容量文件(单个文件规模达到 TB 甚至 PB 级)和百万规模以上的文件数量
- 可以构建在廉价的机器上
【缺点】
- 不适合低延时的数据访问,比如毫秒级的存储数据
- 无法高效地对大量小文件进行存储
- 不支持并发写入、文件随机修改(支持内容追加)
HDFS 组成架构
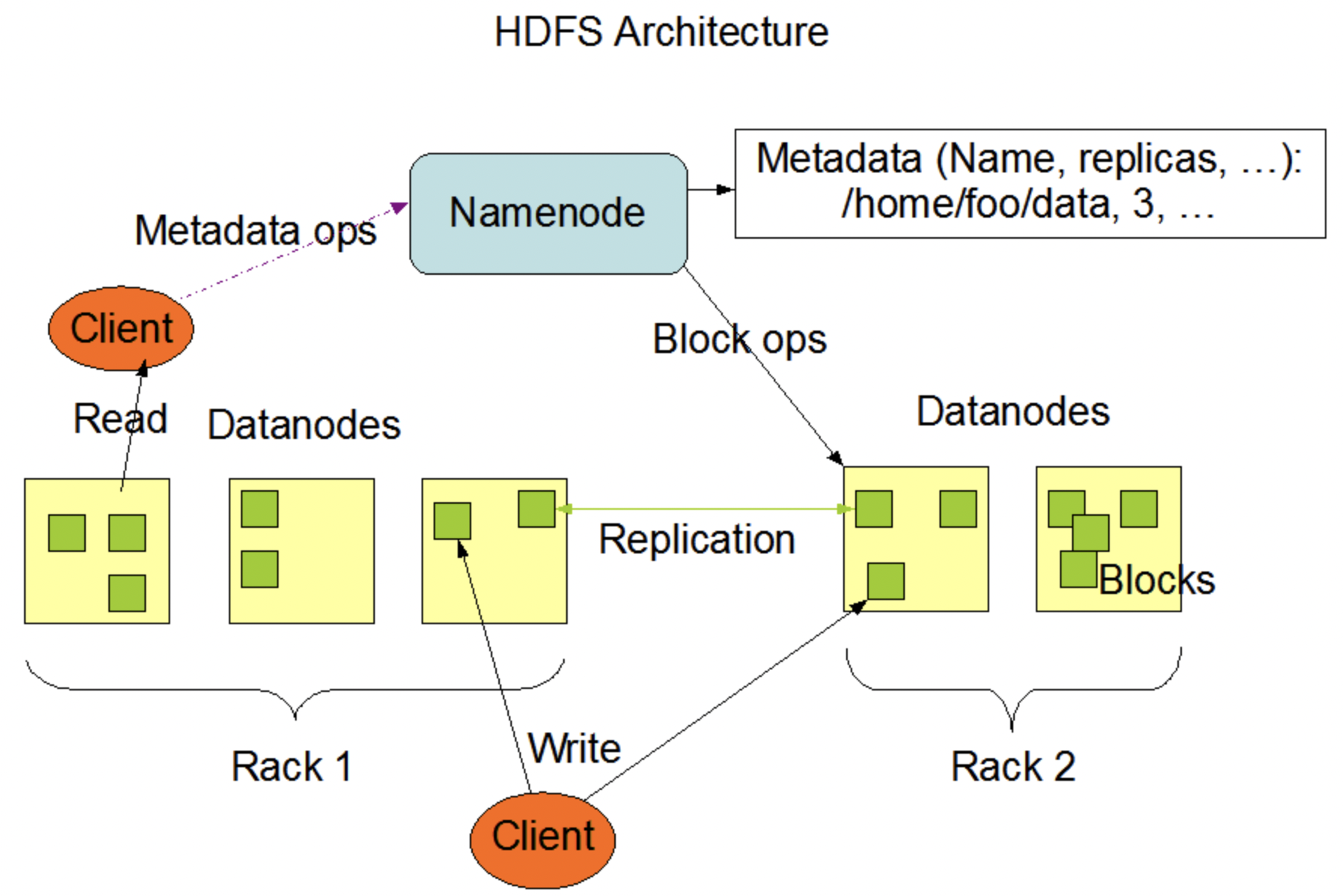
在上图中:
-
NameNode (nn):就是 Master,它是一个主管、管理者。
- 管理 HDFS 的名称空间;
- 配置副本策略;
- 管理数据块 (Block)映射信息,
- 处理客户端读写请求。
-
DataNode (dn):就是 Worker。 NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块
- 执行数据块的读/写操作
-
Secondary NameNode (2nn):并非 NameNode 的热备份,当 NameNode 崩溃的时候,它并不能马上替换NameNode 并提供服务。
- 辅助 NameNode,分担其工作量,比如定期合并 Fsimauge 和 Edits, 并推送给 NameNode;
- 在紧急情况下,可辅助部分恢复 NameNode
-
Client:即客户端。其功能有:
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block(可更改,默认
128MB),然后进行上传; - 与 NameNode 交互,获取文件的位置信息;
- 与 DataNode 交互,读写数据;
- Client 提供一些命令来管理或访问 HDFS,比如 NameNode 格式化;
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block(可更改,默认
1.3 Map-Reduce
MapReduce 概述
MapReduce 定义
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop 集群上。
MapReduce 优缺点
【优点】
- MapReduce 易于编程:用户可以通过简单地实现一些框架接口,就可以完成一个分布式程序。用户只需要关心业务逻辑。
- 良好的扩展性:可以动态增加服务器,解决计算资源不够的问题
- 高容错性:任何节点崩溃后,可以将任务转移到其他节点
- 适合海量数据计算(TB/PB),千台服务器共同计算
【缺点】
- 不擅长实时计算
- 不擅长流式计算
- 不擅长 DAG 有向无环图计算(迭代计算)
以 wordCount 为例子,介绍 MapReduce 流程
-
输入数据
1
2
3
4Hello World Bye World
Goodbye Man
Hello Hadoop Goodbye Hadoop
Goodbye Grid -
输出数据
1
2
3
4
5
6
7<Hello, 2>
<World, 2>
<Bye, 1>
<Goodbye, 3>
<Man, 1>
<Hadoop, 2>
<Grid, 1> -
Mapper-
将
MapTask传给我们的文本内容按行读取为String1
Hello World Bye World
-
根据空格将这一行单词切分成单词
1
2
3
4Hello
World
Bye
World -
将单词输出为
<单词, 1>1
2
3
4<Hello, 1>
<World, 1>
<Bye, 1>
<World, 1>
-
-
Reducer-
汇总各个 key 的个数:
<K, {V}>1
2
3<Hello, [1]>
<World, [1,1]>
<Bye, [1]> -
输出该 key 的总次数:
<K, V>1
2
3<Hello, 1>
<World, 2>
<Bye, 1>
-
-
Driver- 获取配置信息,获取
job对象示例 - 指定本程序
jar包所在的本地路径 - 关联
Mapper/Reducer业务类 - 指定
Mapper输出数据的 kv 类型 - 指定最终输出的数据的 kv 类型
- 指定
job的原始输入文件所在目录 - 指定
job的输出结果所在目录 - 提交作业
- 获取配置信息,获取
2. Spark
与 Hadoop 每次 Map-Reduce 每次计算都要将结果写入磁盘不同,Spark 是一种基于内存的,快速、通用、可扩展的大数据分析计算引擎。
2.1 Spark 与 Hadoop 的区别
-
应用场景不同
Hadoop 和 Spark两者都是大数据框架,但是各自应用场景是不同的。Hadoop是一个分布式数据存储架构,它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,降低了硬件的成本。Spark 是那么一个专门用来对那些分布式存储的大数据进行处理的工具,它要借助 HDFS 的数据存储。
-
处理速度不同
Hadoop 的 MapReduce 是分步对数据进行处理的,从磁盘中读取数据,进行一次处理,将结果写到磁盘,然后在从磁盘中读取更新后的数据,再次进行的处理,最后再将结果存入磁盘,这存取磁盘的过程会影响处理速度。Spark 从磁盘中读取数据,把中间数据放到内存中,完成所有必须的分析处理,将结果写回集群,所以 Spark 更快。
-
容错性不同
Hadoop 将每次处理后的数据都写入到磁盘上,基本谈不上断电或者出错数据丢失的情况。Spark 的数据对象存储在内存中的弹性分布式数据集 RDD,RDD 是分布在一组节点中的只读对象集合,如果数据集一部分丢失,则可以根据于数据衍生过程对它们进行重建。而且 RDD 计算时可以通过 CheckPoint 来实现容错。
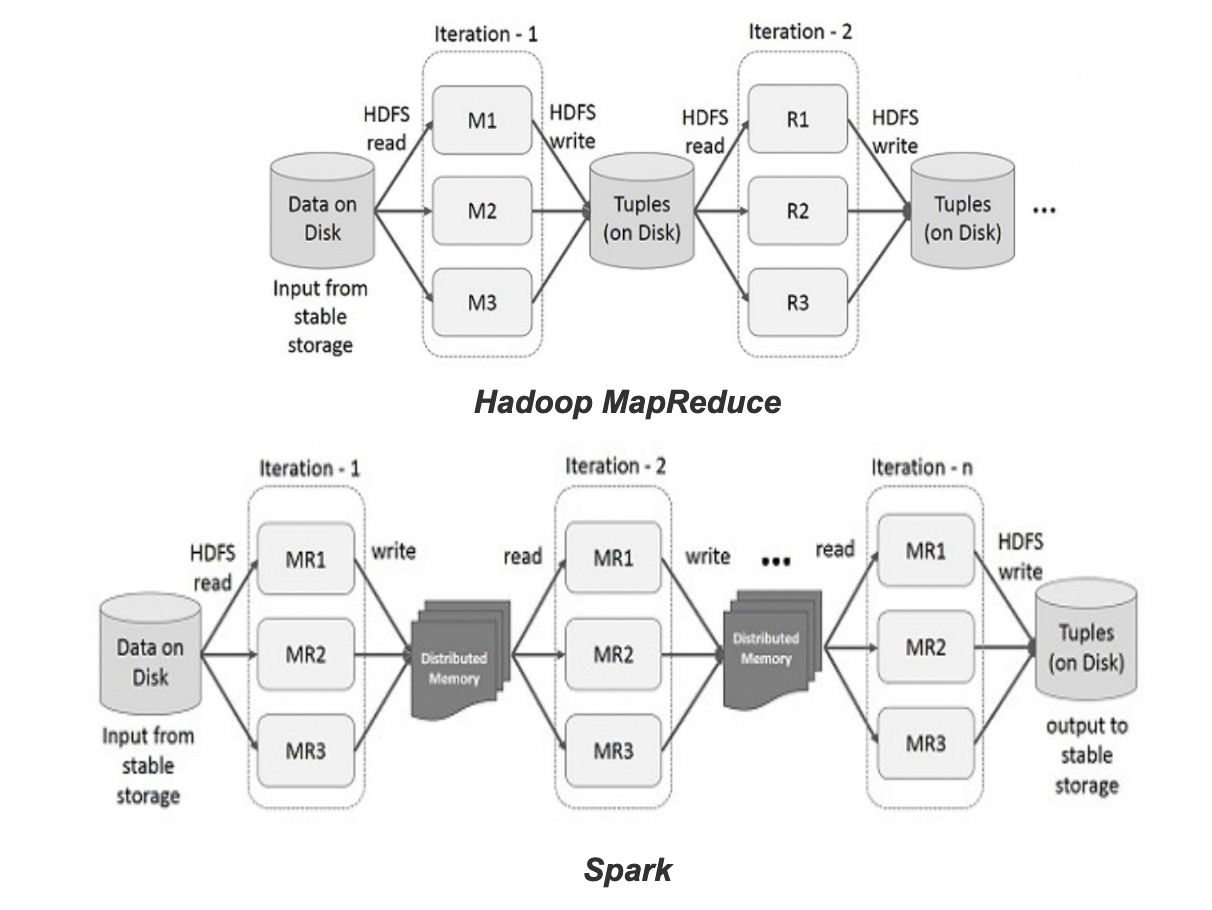
2.2 Spark 的架构
YARN 架构回顾
YARN 主要有 4 类角色,可以从两个层面去看: