写在前面:
本文章不会具体介绍 MPI 的历史发展,以及开发环境的过程配置,点击查看示例 。
本文章将会使用 SimGrid 工具,来为异构分布式环境中的分布式应用程序仿真提供核心功能(模拟一个集群)。
建议使用 Docker 等容器化虚拟环境搭建测试开发平台,以下给出一个可用的 Docker 镜像文件。点击跳转至 DockerHub ,或直接使用如下命令将镜像文件拉取到本地:
1 docker pull henricasanova/ics632_smpi
我们使用 SimGrid 工具来模拟一个集群,集群的配置文件点击此处下载 。为了后续运行方便,我们使用别名 alias 来简化 smpirun 指令的参数:
1 2 3 4 5 SIMGRID=/集群配置文件的地址/ alias smpirun="smpirun -hostfile ${SIMGRID} /archis/cluster_hostfile.txt -platform ${SIMGRID} /archis/cluster_crossbar.xml"
参考资料:
MPI 是高性能计算常用的实现方式,它的全名叫做 Message Passing Interface。顾名思义,它是一个实现了消息传递接口的库(并不是一种语言)。部分的 MPI 实现由一些指定的编程接口(API)组成,可由 C、C++、Fortran,或者有此类库的语言比如 C#、 Java 或者 Python 直接调用。它提供了应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。
MPI 用作基于消息传递的并行编程,它提供了语义丰富的消息通信机制,包括点对点 组播 多播 MPI 标准规定了这些接口的调用规范和语义,不同的实现可能采用不同的优化策略。
一个 MPI 程序基本由四个部分组成分:MPI 头文件初始化 MPI 环境 、消息交换处理及计算 等以及退出 MPI 环境 。
下面我们来介绍一些 MPI 中的经典概念:
第一个概念是通讯器 MPI 的所有通信都必须在某个通讯器中进行。
秩 唯一标识 秩 (rank),进程间显性地通过指定秩来进行通信。消息 MPI 程序在进程间传递的数据。它由通讯器、源地址、目的地址、消息标签(tag)和数据构成。
通信 缓冲区 buffer:在用户应用程序中定义的用于***保存发送和接收数据的【地址空间】*** 。
在 C 语言代码中,MPI 的实现形式如下
1 2 3 4 5 6 7 8 9 10 #include <mpi.h> MPI_Init(int * argc, char *** argv); MPI_Comm_rank(MPI_Comm communicator, int * rank); MPI_Comm_size(MPI_Comm communicator, int * size); MPI_Get_processor_name(char * name, int * name_length); MPI_Xxxxx(); MPI_Finalize();
在 【MPI_Init】 的过程中,所有 MPI 的全局变量或者内部变量都会被创建。
举例来说,一个通讯器 communicator 会根据所有可用的进程被创建出来(进程是我们通过 MPI 运行时的参数指定的),然后每个进程会被分配独一无二的秩 rank。
【MPI_Comm_rank】 会返回当前调用线程在通讯器 communicator 进程标示号 communicator 中每个进程会以此得到一个从 0 开始递增的数字 rank 值。rank 值主要是用来指定发送或者接受信息时对应的进程。
【MPI_Comm_size】 会返回 communicator 的大小,也就是 communicator 中可用的进程数量。在我们的例子中,MPI_COMM_WORLD(这个 communicator 是 MPI 帮我们生成的)这个变量包含了当前 MPI 任务中所有的进程,因此在我们的代码里的这个调用会返回所有的可用的进程数目
【MPI_Get_processor_name】:会得到当前进程实际跑的时候所在的处理器名字。
【MPI_Finalize】 是用来清理 MPI 环境的。这个调用之后就没有 MPI 函数可以被调用了。
我们用以上介绍过的函数编写一个简单的演示示例,用多线程间消息传递的方式来打印一段简单输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <mpi.h> #include <stdio.h> int main (int argc, char ** argv) { MPI_Init(NULL , NULL ); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); printf ("Hello world from processor %s, rank %d out of %d processors\n" , processor_name, world_rank, world_size); MPI_Finalize(); }
接下来,我们使用 mpicc 命令编译这个程序,mpirun 指定使用多少个进程来运行这个程序:
1 2 mpicc HelloWorld.c -o HelloWorld mpirun -n 4 HelloWorld
输出结果如下
1 2 3 4 Hello world from processor c0f2333487ce, rank 1 out of 4 processors Hello world from processor c0f2333487ce, rank 2 out of 4 processors Hello world from processor c0f2333487ce, rank 3 out of 4 processors Hello world from processor c0f2333487ce, rank 0 out of 4 processors
或者使用 SimGrid 工具来模拟一个集群,运行(smpirun -np 24 Helloworld)结果如下
1 2 3 4 5 6 Hello world from processor host-0.hawaii.edu, rank 0 out of 24 processors Hello world from processor host-1.hawaii.edu, rank 1 out of 24 processors Hello world from processor host-2.hawaii.edu, rank 2 out of 24 processors ... Hello world from processor host-22.hawaii.edu, rank 22 out of 24 processors Hello world from processor host-23.hawaii.edu, rank 23 out of 24 processors
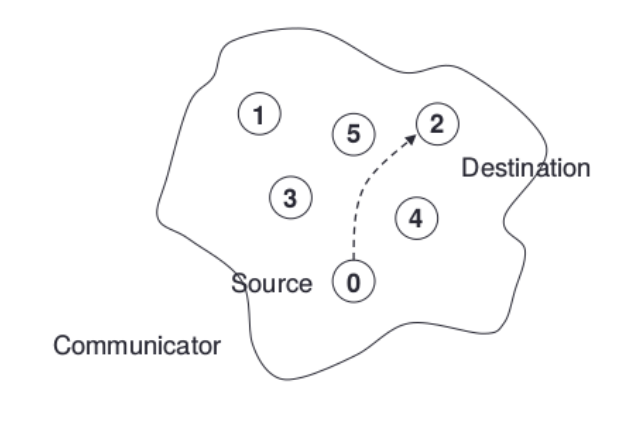
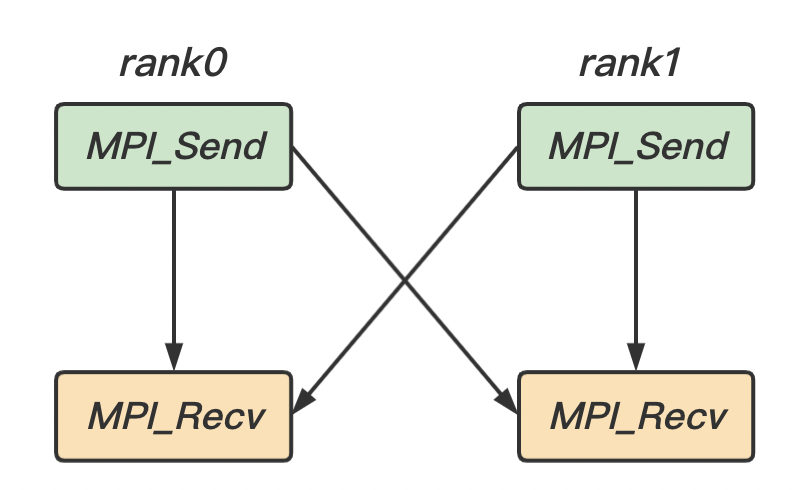
所谓的点对点通信,就是在如上图所示中通讯器中,一个进程 0, Source 与另一个进程 2, Destination 之间的通信。当然也存在多对多的通信,我们将在后面讲解。
在一次通信中,离不开消息的发送 接收
MPI 的发送和接收方法是按以下方式进行的:
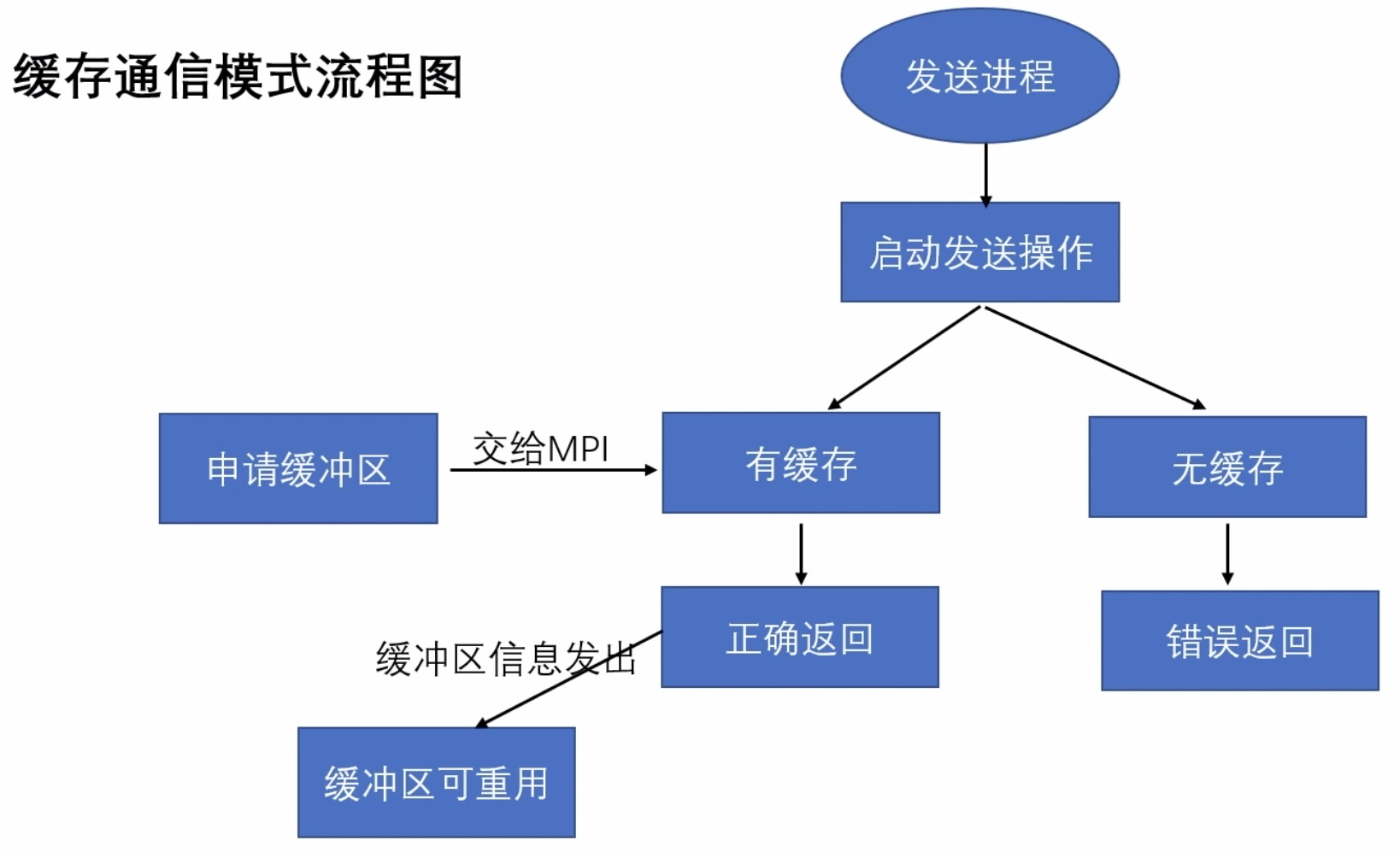
【缓存区】
开始的时候,A 进程决定要发送一些消息给 B 进程。A 进程就会把需要发送给 B 进程的所有数据打包好,放到一个缓存
因为所有数据会被打包到一个大的信息里面,因此缓存常常会被比作信封 (就像我们把好多信纸打包到一个信封里面然后再寄去邮局)。数据打包进缓存之后,通信设备(通常是网络)就需要负责把信息传递到正确的地方。这个正确的地方也就是根据特定秩确定的那个进程。
【阻塞/非阻塞】
阻塞式:当一个进程发送或接收一个较大的信息,该进程会一直阻塞在当前的(发送或接收)状态,直至发送或接收完成。
非阻塞式:同样的,当一个进程发送或接收一条消息时,进程不会阻塞在当前状态,而是会继续向下执行。它只保证调用函数的时候通信开始了,然后马上返回,返回的时候不保证完成了。我们必须另外调用一个 MPI_Wait 来确保通信完成,而这里的“完整”指的也是“信封和数据都已经被转存到别的地方
【同步发送/异步发送】
同步 等到接收进程完成接收 异步 只要将消息完全发送 不必在乎消息是否被接收
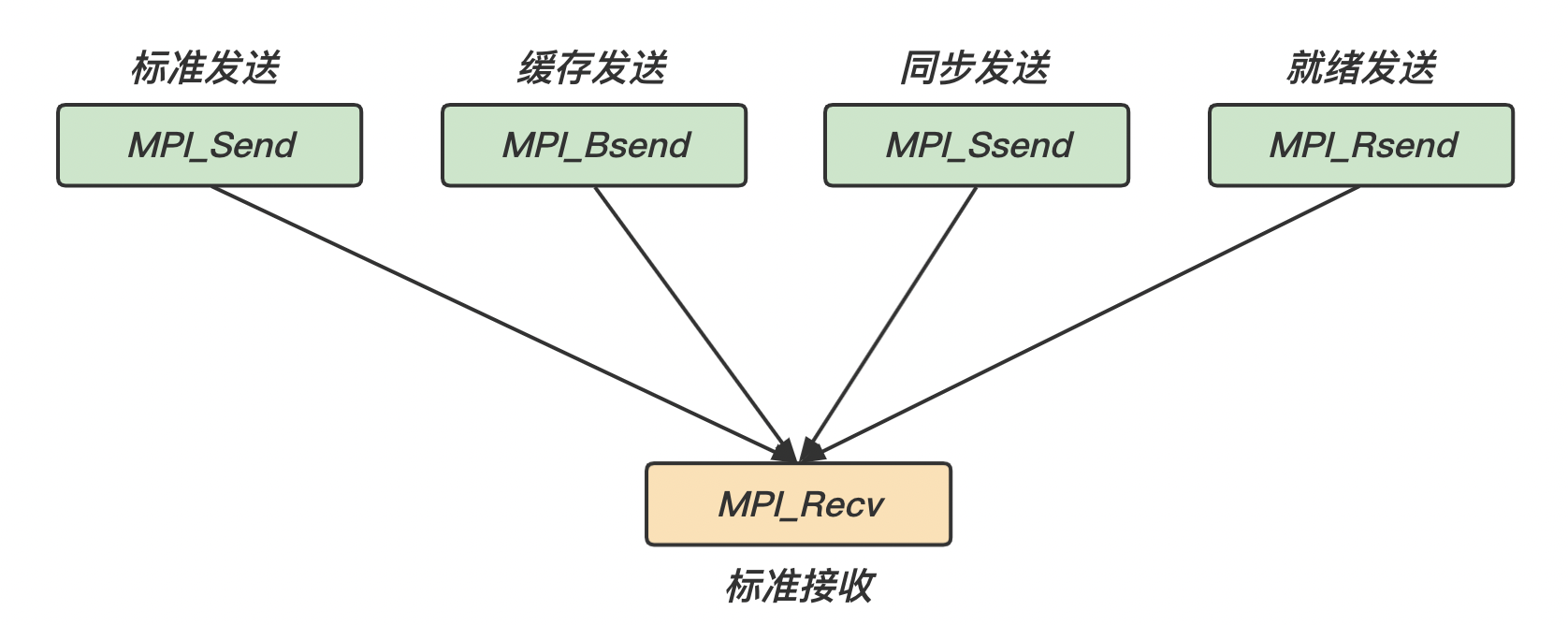
而基于以上几点,我们可以组合出许多不同种类的发送/接收模式:
发送/接收模式
描述
关键字
非阻塞式
同步发送Synchronous Send )
发送进程会等待接收的完成
MPI_Ssend()MPI_Issend()
缓存发送Buffered Send )
只要缓冲区 buffer 可重入
MPI_Bsend()MPI_Ibsend()
标准发送Standard Send )
即可以是同步 缓存
MPI_Send()MPI_Isend()
就绪发送Ready Send )
只能在匹配的接收开始的时候,才能开始发送
MPI_Rsend()MPI_Irsend()
标准接收Standard Send )
消息完全到达时接收完成(总是同步的)
MPI_Recv()MPI_Irecv()
首先,让我们来看一下 MPI 标准发送和标准接收方法的定义:
1 2 3 MPI_Send( type * data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator)
1 2 3 MPI_Recv( type * data, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm communicator, MPI_Status * status)
或者在正式接收之前,可以在任何时候使用 MPI_Probe 查询消息大小,但是其并不接收任何消息 探查
1 2 MPI_Probe( int source, int tag, MPI_Comm communicator, MPI_Status* status)
其中:
type * data:待发送/接收的数据地址
count:待发送/接收的数据个数
datatype:待发送/接收的数据类型
MPI_Datatype对应 C 语言的数据结构
MPI_SHORTshort int
MPI_INTint
MPI_LONGlong int
MPI_LONG_LONGlong long int
MPI_UNSIGNED_CHARunsigned char
MPI_UNSIGNED_SHORTunsigned short int
MPI_UNSIGNEDunsigned int
MPI_UNSIGNED_LONGunsigned long int
MPI_UNSIGNED_LONG_LONGunsigned long long int
MPI_FLOATfloat
MPI_DOUBLEdouble
MPI_LONG_DOUBLElong double
MPI_BYTEchar
destination:发送到目的进程的 rank
source:接收到源进程的 rank
MPI_ANY_SOURCE:接收者可以给 source 指定一个任意值 MPI_ANY_SOURCE,标识任何进程
tag:通信标示
MPI_ANY_TAG:表示给 tag 一个任意值 MPI_ANY_TAG,则任何 tag 都是可接收的
MPI_Comm communicator:通信域
MPI_Status * status:设置接收端的状态。在这个结构体中,包含三个主要信息,包括
发送端秩 rank: 发送端的秩存储在结构体的 MPI_SOURCE 元素中。可以通过 status.MPI_SOURCE 访问秩。
消息的标签 tag:消息的标签可以通过结构体的 MPI_TAG 元素访问(status.MPI_TAG)。
消息的长度 status 结构体中 datatype 类型数据的个数写入到 count 地址。
1 2 3 4 MPI_Get_count( MPI_Status* status, MPI_Datatype datatype, int * count)
MPI_Get_count(MPI_Status* status , MPI_Datatype datatype ,int* count)
在接收端可以使用 MPI_Get_count() 函数得到实际接收到的消息个数,并复制到 count 的地址下
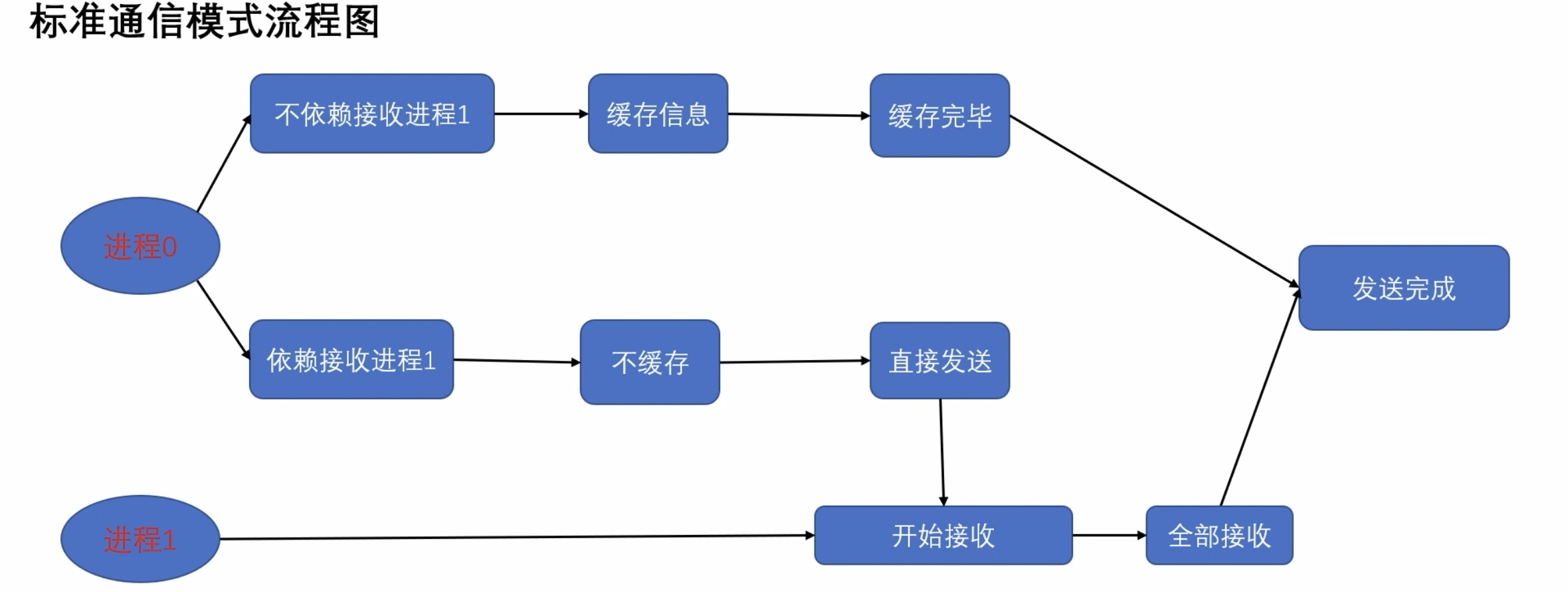
在 MPI 中采用标准通信模式时,是否能够成功返回取决于缓存区 buffer 是否可以被重新写入(即,消息是否发送完成)。
在下图中,
如果 MPI 维护的 buffer 没有满 缓存模式 buffer,然后即可返回;
如果 MPI 维护的 buffer 已经满了 同步模式
点对点通信的语序遵循 FIFO
1 2 3 4 进程0 { MPI_Send(data1, 1 , MPI_INT, rank1, tag1, comm); MPI_Send(data2, 1 , MPI_INT, rank1, tag2, comm); }
1 2 3 4 进程1 { MPI_Recv(data1, 1 , MPI_INT, rank0, tag1, comm, status1); MPI_Recv(data2, 1 , MPI_INT, rank0, tag2, comm, status2); }
如果标准接收 MPI_Recv() 方法没有返回 一直等待接收
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <mpi.h> #include <stdio.h> int main (int argc, char ** argv) { MPI_Init(&argc, &argv); int size; MPI_Comm_size(MPI_COMM_WORLD, &size); int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); if (size != 2 ) { printf ("*** 这个程序需要 2 个进程!当前进程数为 %d ***\n" , size); MPI_Abort(MPI_COMM_WORLD, 1 ); } int sendBuf; int recvBuf; MPI_Status status1, status2; if (rank == 0 ) { sendBuf = 0 ; MPI_Send(&sendBuf, 1 , MPI_INT, 1 , 1 , MPI_COMM_WORLD); printf ("[进程0] : 标准发送模式, 发送数据为 %d , tag=1\n" , sendBuf); MPI_Recv(&recvBuf, 1 , MPI_INT, 1 , 2 , MPI_COMM_WORLD, &status1); printf ("[进程0] : 标准发送模式, 接收数据为 %d , tag=2\n" , recvBuf); } else if (rank == 1 ) { sendBuf = 1 ; MPI_Send(&sendBuf, 1 , MPI_INT, 0 , 2 , MPI_COMM_WORLD); printf ("[进程1] : 标准发送模式, 发送数据为 %d , tag=2\n" , sendBuf); MPI_Recv(&recvBuf, 1 , MPI_INT, 0 , 1 , MPI_COMM_WORLD, &status2); printf ("[进程1] : 标准发送模式, 接收数据为 %d , tag=1\n" , recvBuf); } MPI_Finalize(); }
编译与运行
1 2 mpicc standard.c -o standard mpirun -n 2 standard
程序输出
1 2 3 4 [进程0] : 标准发送模式, 发送数据为 0 , tag=1 [进程1] : 标准发送模式, 发送数据为 1 , tag=2 [进程1] : 标准发送模式, 接收数据为 0 , tag=1 [进程0] : 标准发送模式, 接收数据为 1 , tag=2
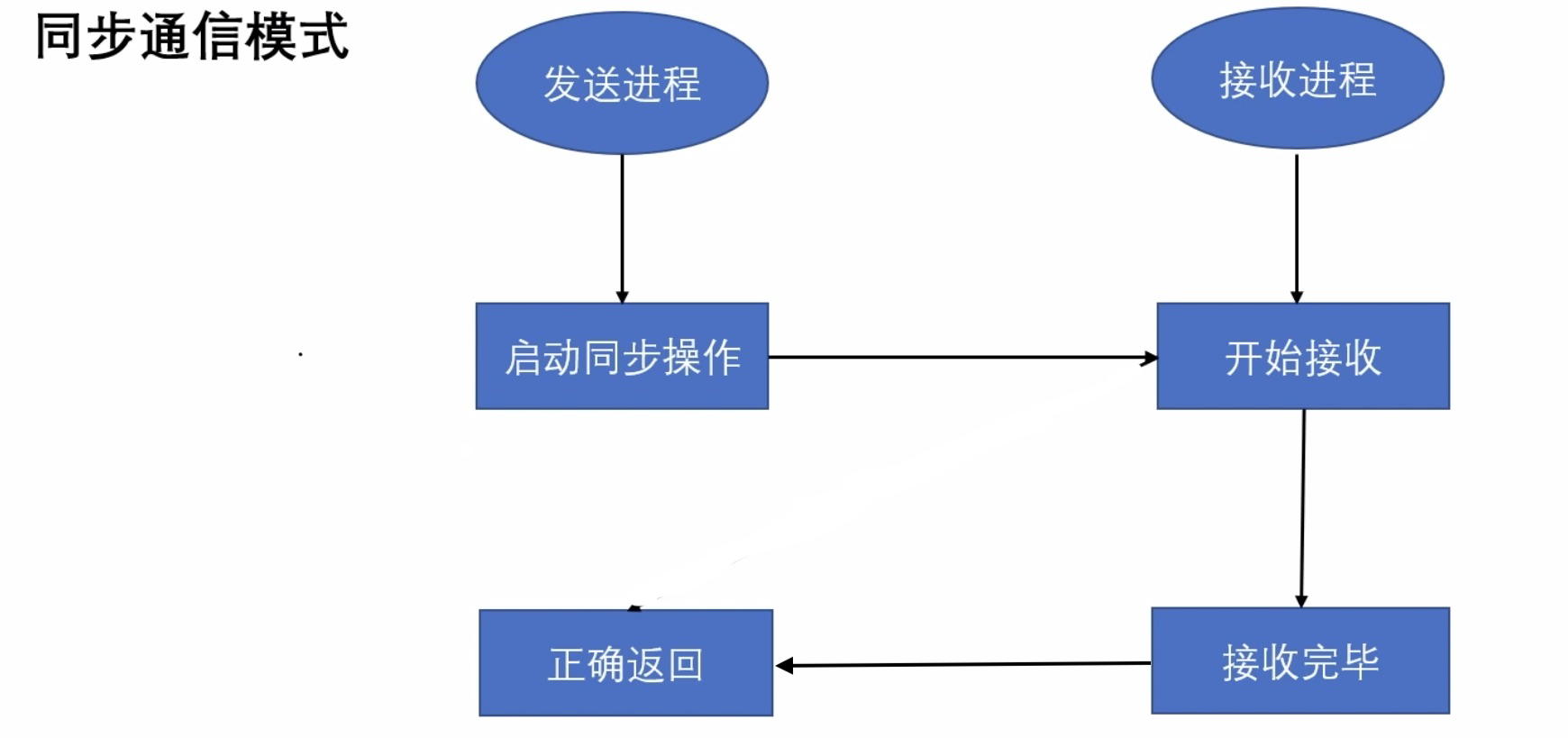
同步通信模式与标准通信相似,我们来看一下 MPI 同步发送方法的定义:
1 2 3 MPI_Ssend( type* data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator)
data:待发送数据的地址 count:待发送/接收的数据个数 datatype:待发送/接收的数据类型 destination:发送到目的进程的 ranktag:通信标示MPI_Comm communicator:通信域
在标准通信 发送进程的正确返回 不需要依靠接收进程的状态 MPI_Send() 便会成功返回。
在同步模式中,我们规定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <mpi.h> #include <stdio.h> #include <stdlib.h> int main (int argc, char ** argv) { MPI_Init(&argc, &argv); int size; MPI_Comm_size(MPI_COMM_WORLD, &size); int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); if (size != 2 ) { printf ("*** 这个程序需要 2 个进程!当前进程数为 %d ***\n" , size); MPI_Abort(MPI_COMM_WORLD, 1 ); } double sendData[3 ] = {1.11111111 , 2.22222222 , 3.33333333 }; int sendBufferSize; double recvData[3 ]; MPI_Status status; if (rank == 0 ) { MPI_Send(&sendData[0 ], 1 , MPI_DOUBLE, 1 , 1 , MPI_COMM_WORLD); printf ("[%s | 进程0] : MPI_Send(标准), 发送数据为 %f , tag=1\n" , processor_name, sendData[0 ]); MPI_Ssend(&sendData[1 ], 2 , MPI_DOUBLE, 1 , 2 , MPI_COMM_WORLD); printf ("[%s | 进程0] : MPI_Ssend(同步), 发送数据为 [%f, %f] , tag=2\n" , processor_name, sendData[1 ], sendData[2 ]); } else if (rank == 1 ) { int recvCount; MPI_Recv(&recvData, 3 , MPI_DOUBLE, 0 , 1 , MPI_COMM_WORLD, &status); printf ("[%s | 进程1] : 缓存发送模式, 接收数据为 [%f, %f, %f] , tag=1\n" , processor_name, recvData[0 ], recvData[1 ], recvData[2 ]); MPI_Get_count(&status, MPI_DOUBLE, &recvCount); printf ("[%s | 进程1] : 实际接收到的数据数量: %d\n" , processor_name, recvCount); MPI_Recv(&recvData, 3 , MPI_DOUBLE, 0 , 2 , MPI_COMM_WORLD, &status); printf ("[%s | 进程1] : 缓存发送模式, 接收数据为 [%f, %f, %f] , tag=1\n" , processor_name, recvData[0 ], recvData[1 ], recvData[2 ]); MPI_Get_count(&status, MPI_DOUBLE, &recvCount); printf ("[%s | 进程1] : 实际接收到的数据数量: %d\n" , processor_name, recvCount); } MPI_Finalize(); }
输出结果
1 2 3 4 5 6 [c0f2333487ce | 进程0] : MPI_Send(标准), 发送数据为 1.111111 , tag=1 [c0f2333487ce | 进程1] : 缓存发送模式, 接收数据为 [1.111111, 0.000000, 0.000000] , tag=1 [c0f2333487ce | 进程1] : 实际接收到的数据数量: 1 [c0f2333487ce | 进程1] : 缓存发送模式, 接收数据为 [2.222222, 3.333333, 0.000000] , tag=1 [c0f2333487ce | 进程1] : 实际接收到的数据数量: 2 [c0f2333487ce | 进程0] : MPI_Ssend(同步), 发送数据为 [2.222222, 3.333333] , tag=2
如果我们在设计 MPI 程序时,对标准通信模式并不满意或者希望对缓冲区进行直接控制,我们可以使用缓存模式
注意事项:(1)程序员需要对通信缓冲区进行申请 使用 释放
相同的,让我们来看一下 MPI 缓存发送的方法的定义:
1 2 3 MPI_Bsend( type * sendBuffer, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator)
与标准模式类似:
sendBuffer:待发送数据的缓冲区地址 count:待发送/接收的数据个数 datatype:待发送/接收的数据类型 destination:发送到目的进程的 ranktag:通信标示MPI_Comm communicator:通信域
在 MPI 中采用缓存通信模式时,缓存是由程序员来维护的。
那么,我们该如何申请和释放缓冲区呢?
申请缓冲区
1 2 3 4 int MPI_Buffer_attach ( type * buffer, int size )
释放缓冲区
1 2 3 4 int MPI_Buffer_detach ( type * buffer, int * size )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <mpi.h> #include <stdio.h> #include <stdlib.h> int main (int argc, char ** argv) { MPI_Init(&argc, &argv); int size; MPI_Comm_size(MPI_COMM_WORLD, &size); int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); if (size != 2 ) { printf ("*** 这个程序需要 2 个进程!当前进程数为 %d ***\n" , size); MPI_Abort(MPI_COMM_WORLD, 1 ); } double sendData[3 ] = {1.23456789 , 1.23456789 , 1.23456789 }; int sendBufferSize; double recvData[3 ]; MPI_Status status; if (rank == 0 ) { MPI_Pack_size(3 , MPI_DOUBLE, MPI_COMM_WORLD, &sendBufferSize); double * tempBuffer = (double *) malloc (sendBufferSize+MPI_BSEND_OVERHEAD); MPI_Buffer_attach(tempBuffer, sendBufferSize+MPI_BSEND_OVERHEAD); MPI_Bsend(&sendData, 3 , MPI_DOUBLE, 1 , 1 , MPI_COMM_WORLD); printf ("[%s | 进程0] : 缓存发送模式, 发送数据为 [%f, %f, %f] , tag=1\n" , processor_name, sendData[0 ], sendData[1 ], sendData[2 ]); MPI_Buffer_detach(tempBuffer, &sendBufferSize); } else if (rank == 1 ) { MPI_Recv(&recvData, 3 , MPI_DOUBLE, 0 , 1 , MPI_COMM_WORLD, &status); printf ("[%s | 进程1] : 缓存发送模式, 接收数据为 [%f, %f, %f] , tag=1\n" , processor_name, recvData[0 ], recvData[1 ], recvData[2 ]); int recvCount; MPI_Get_count(&status, MPI_DOUBLE, &recvCount); printf ("[%s | 进程1] : 实际接收到的数据数量: %d\n" , processor_name, recvCount); } MPI_Finalize(); }
输出结果
1 2 3 [c0f2333487ce | 进程0] : 缓存发送模式, 发送数据为 [1.234568, 1.234568, 1.234568] , tag=1 [c0f2333487ce | 进程1] : 缓存发送模式, 接收数据为 [1.234568, 1.234568, 1.234568] , tag=1 [c0f2333487ce | 进程1] : 实际接收到的数据数量: 3
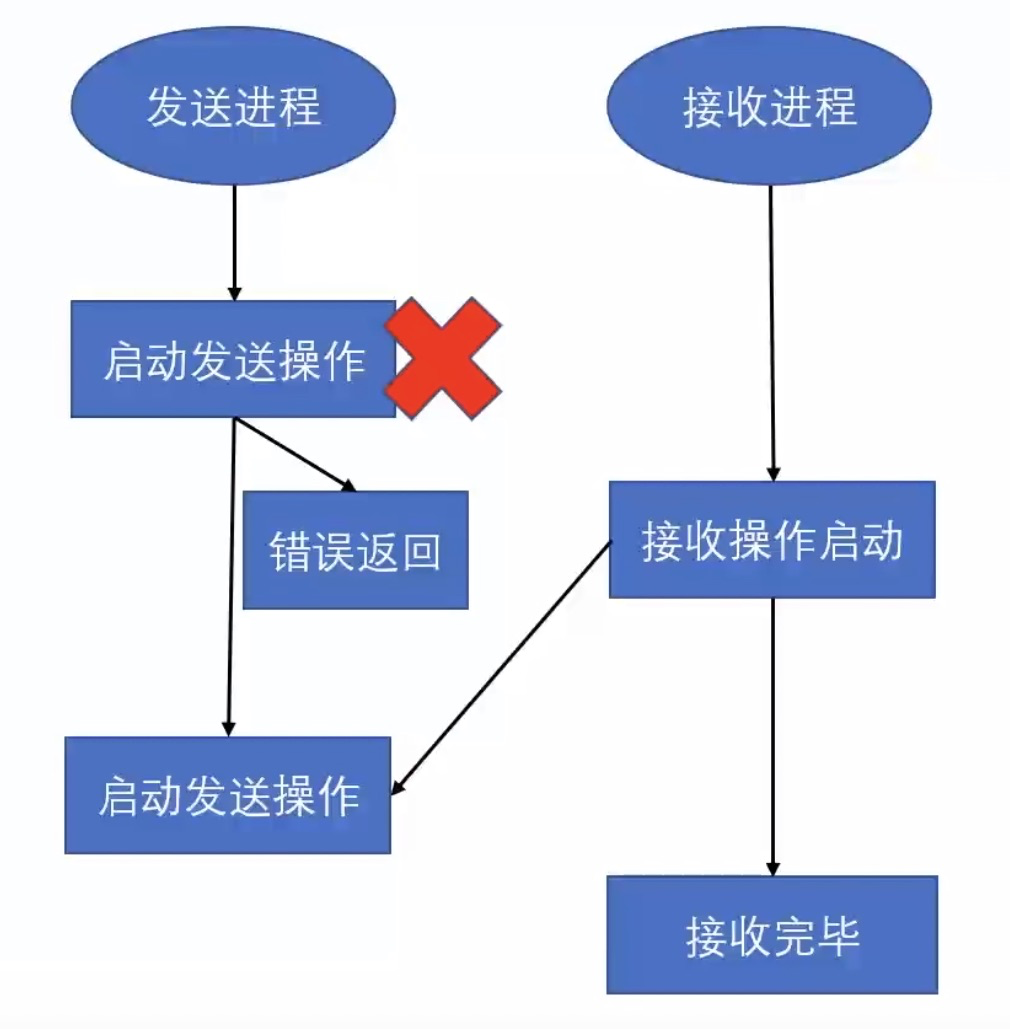
首先,让我们来看一下 MPI 就绪发送方法的定义:
1 2 3 MPI_Rsend( type * data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator)
就绪模式的特殊之处就在于它要求接收操作的启动 先于发送操作的启动
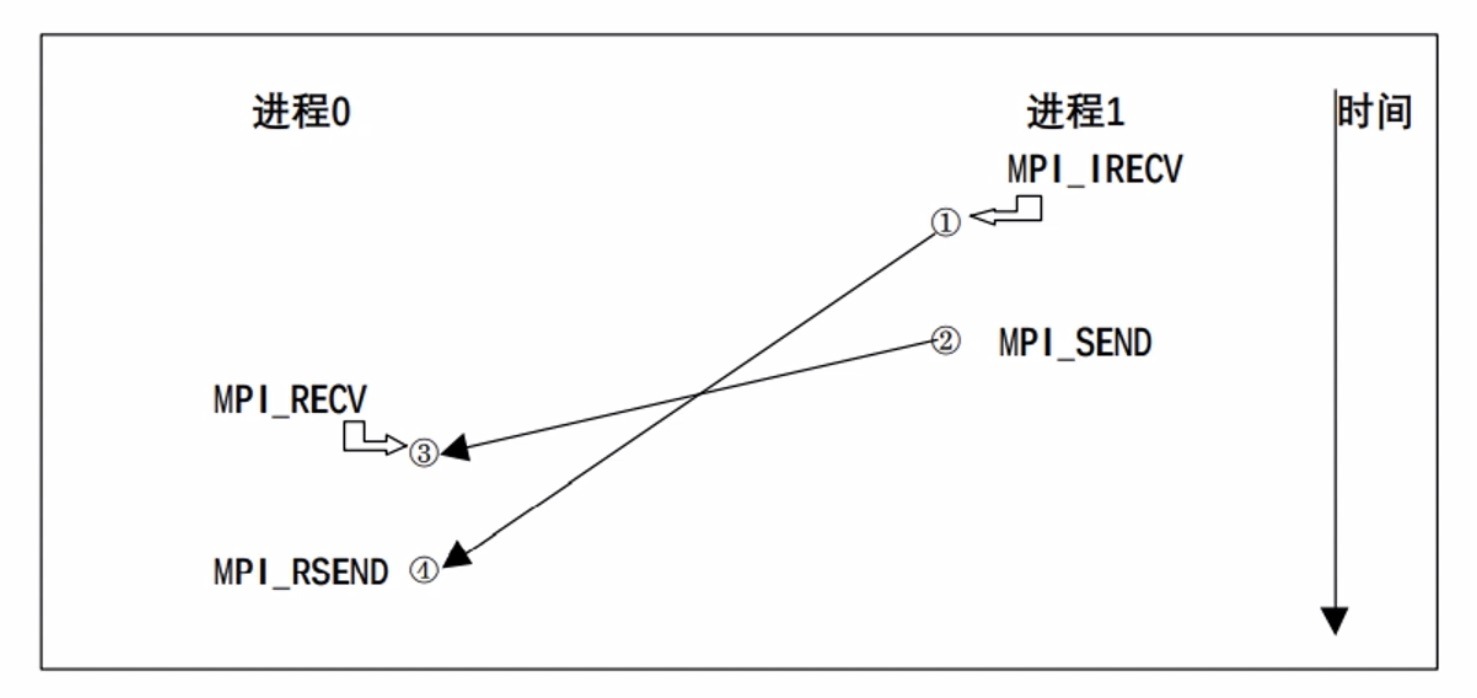
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <mpi.h> #include <stdio.h> #include <stdlib.h> int main (int argc, char ** argv) { MPI_Init(&argc, &argv); int size; MPI_Comm_size(MPI_COMM_WORLD, &size); int rank; MPI_Comm_rank(MPI_COMM_WORLD, &rank); char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); if (size != 2 ) { printf ("*** 这个程序需要 2 个进程!当前进程数为 %d ***\n" , size); MPI_Abort(MPI_COMM_WORLD, 1 ); } double sendData[3 ] = {1.11111111 , 2.22222222 , 3.33333333 }; int sendBufferSize; double recvData[3 ]; MPI_Status status, statusReady; MPI_Request request; if (rank == 0 ) { char recvReady; MPI_Recv(&recvReady, 1 , MPI_BYTE, 1 , 2 , MPI_COMM_WORLD, &statusReady); printf ("[%s | 进程0] : MPI_Recv(普通接收), 接收数据为 %c , \t\t\t\t\t tag=1\n" , processor_name, recvReady); MPI_Rsend(&sendData, 3 , MPI_DOUBLE, 1 , 1 , MPI_COMM_WORLD); printf ("[%s | 进程0] : MPI_Rsend(就绪发送), 发送数据为 [%f, %f, %f] , \t tag=2\n" , processor_name, sendData[0 ], sendData[1 ], sendData[2 ]); } else if (rank == 1 ) { MPI_Irecv(&recvData, 3 , MPI_DOUBLE, 0 , 1 , MPI_COMM_WORLD, &request); char sendReady= 'R' ; MPI_Send(&sendReady, 1 , MPI_BYTE, 0 , 2 , MPI_COMM_WORLD); printf ("[%s | 进程1] : MPI_Send(普通), 发送数据为 %c , \t\t\t\t\t tag=1\n" , processor_name, sendReady); MPI_Wait(&request, &status); printf ("[%s | 进程1] : MPI_Irecv(非阻塞接收), 接收数据为 [%f, %f, %f] , \t tag=2\n" , processor_name, recvData[0 ], recvData[1 ], recvData[2 ]); } MPI_Finalize(); }
上述程序的逻辑如下:
输出如下
1 2 3 4 [c0f2333487ce | 进程1] : MPI_Send(普通), 发送数据为 R , tag=1 [c0f2333487ce | 进程0] : MPI_Recv(普通接收), 接收数据为 R , tag=1 [c0f2333487ce | 进程0] : MPI_Rsend(就绪发送), 发送数据为 [1.111111, 2.222222, 3.333333], tag=2 [c0f2333487ce | 进程1] : MPI_Irecv(非阻塞接收), 接收数据为 [1.111111, 2.222222, 3.333333], tag=2
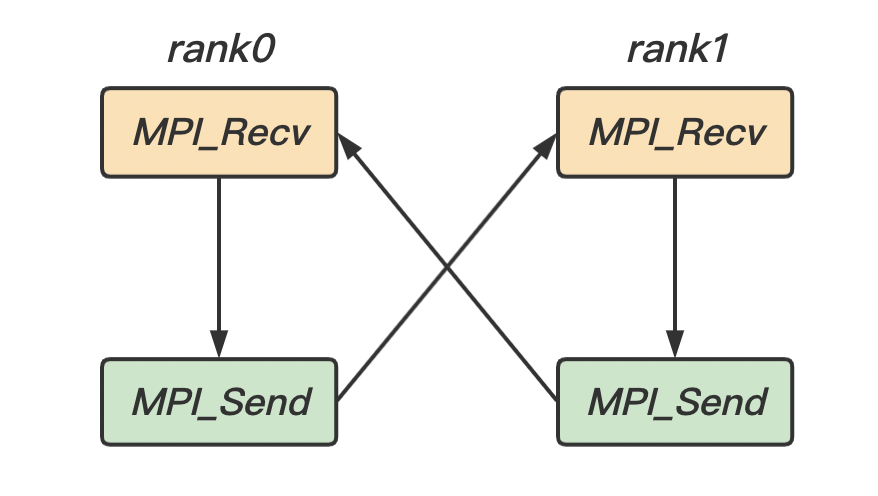
在阻塞式 同步式 可能会发生死锁
可能会发生死锁的情形:
在同步阻塞模式 资源依赖中的环
在普通阻塞模式 缓冲区空间耗尽
在缓存阻塞模式下不太可能出现死锁,但是程序员需要维护缓冲区,当缓冲区空间耗尽时,圆形会失败。
1 2 3 4 5 6 7 8 9 MPI_Comm_Rank(communicator, &rank); if (rank == 0 ){ MPI_Recv(recvBuf, 1 , MPI_INT, rank1, tag1, comm, status1); MPI_Send(sendBuf, 1 , MPI_INT, rank1, tag2, comm); } if (rank == 1 ){ MPI_Recv(recvBuf, 1 , MPI_INT, rank0, tag2, comm, status1); MPI_Send(sendBuf, 1 , MPI_INT, rank0, tag1, comm); }
在这种情况下,我们可以知道两个进程 rank0 与 rank1 都因为等待对方的发送而陷入死锁。也可以画出这个系统的资源依赖图(如下图)。可以看出在图中存在环 发生死锁
那么该如何避免死锁呢?
消除资源依赖图中的环 将阻塞模式改为非阻塞模式
我们改写上述代码,使其不会发生死锁(或者将阻塞式改为非阻塞式):
1 2 3 4 5 6 7 8 9 MPI_Comm_Rank(communicator, &rank); if (rank == 0 ){ MPI_Send(sendBuf, 1 , MPI_INT, rank1, tag2, comm); MPI_Recv(recvBuf, 1 , MPI_INT, rank1, tag1, comm, status1); } if (rank == 1 ){ MPI_Send(sendBuf, 1 , MPI_INT, rank0, tag1, comm); MPI_Recv(recvBuf, 1 , MPI_INT, rank0, tag2, comm, status1); }
参考资料:非阻塞通信
我们前面说到,非阻塞式是当一个进程发送或接收一条消息时,进程不会阻塞在当前状态,而是会继续向下执行。它只保证调用函数的时候通信开始 马上返回 不保证完成
让我们来看一下 MPI 非阻塞标准发送/接收方法的定义:(其余的三种通信模式和阻塞通信的函数形式类似,只是函数名称修改了一下,这里不做详细介绍)
1 2 3 4 5 6 7 8 9 MPI_Isend( void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request )
1 2 3 4 5 6 7 8 9 MPI_Irecv( void * buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request * request )
1 2 3 4 5 6 7 8 9 10 11 MPI_Issend(void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request) MPI_Ibsend(void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request) MPI_Irsend(void * buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request * request)
那么我们如何知道一个消息发送/接收的状态呢?
由于非阻塞通信返回并不意味着该通信已经完成,因此 MPI 提供了一个非阻塞通信对象: MPI_Request 来查询通信的状态。通过结合 MPI_Request 和下面的一些函数,我们等待或者检测阻塞通信。
对于单个非阻塞通信来说,可以使用下面两个函数来等待或者检测非阻塞通信。其中
MPI_Wait 会阻塞当前进程,一直等到相应的非阻塞通信完成之后再返回 MPI_Test 只是用来检测通信是否完成 立即返回 flag 置为 true,如果通信还没完成,则将 flag 置为 false。
1 2 3 4 5 6 7 8 9 10 MPI_Wait( MPI_Request* request, MPI_Status* status ); MPI_Test( MPI_Request* request, int * flag, MPI_Status* status );
前面提到的通信都是点到点通信,这里介绍组通信。MPI 组通信和点到点通信的一个重要区别就在于:
它需要一个特定组内的所有进程
组通信在各个进程中的调用方式完全相同
组通信一般实现三个功能:
通信 同步 特定点的执行进度保持一致 计算
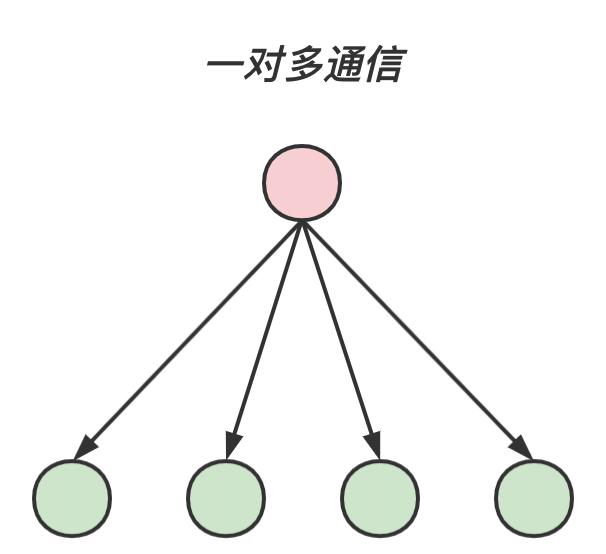
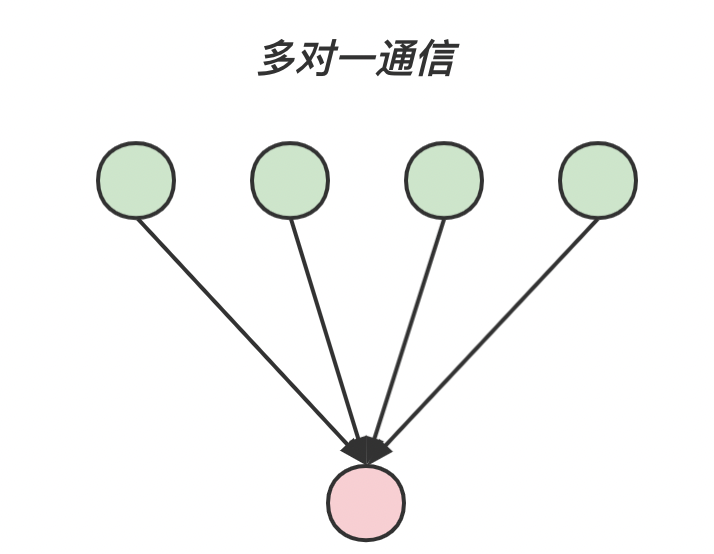
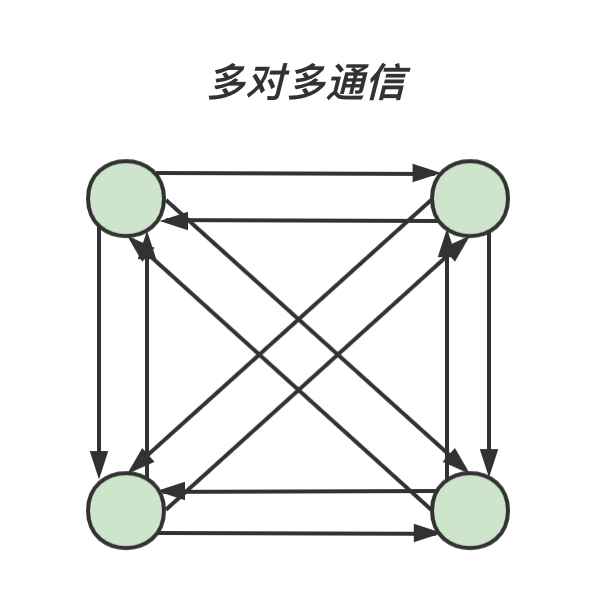
对于组通信来说,按照通信方向的不同,可以分为以下三种:一对多通信 多对一通信 多对多通信
一对多通信 root进程对多个进程发送信息;
多对一通信 root 进程发送信息;
多对多通信
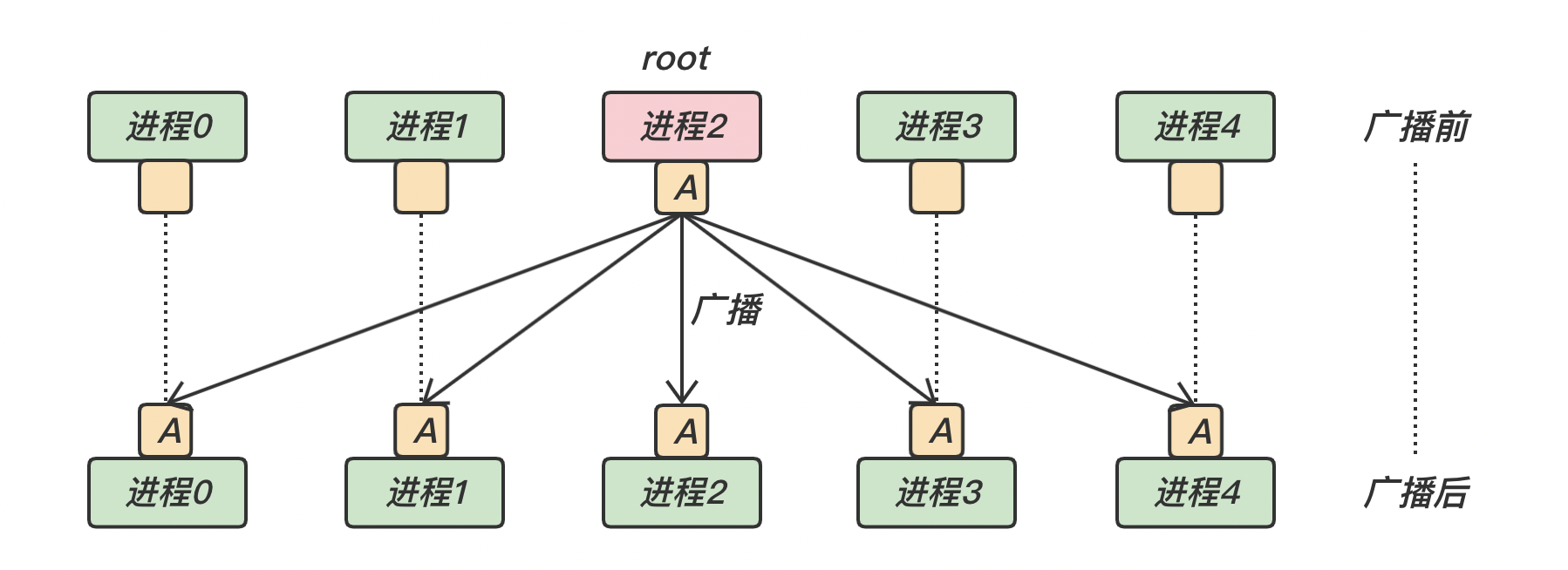
MPI_BcastMPI_Bcast 是一对多通信 root 进程还是其它的进程)都使用同一个通信域 comm 和根标识 root,其执行结果是将根进程消息缓冲区的消息拷贝到其他的进程中去。下面是 MPI_Bcast 的函数原型:
1 2 3 4 5 6 7 int MPI_Bcast ( void * buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm ) ;
对于广播调用,不论是广播消息的根进程,还是从根接收消息的其他进程,在调用形式上完全一致 根进程 元素个数 数据类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> #include <stdlib.h> #include <mpi.h> int main (int argc, char *argv[]) { int value, rank; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); do { if (rank == 0 ) { printf ("\n[进程%d] : 请输入需要广播的值 (小于0时, 程序退出)\n" , rank); scanf ("%d" , &value); } MPI_Bcast(&value, 1 , MPI_INT, 0 , MPI_COMM_WORLD); printf ("[进程%d] : 收到来自 [进程0] 的广播, 接收数据为 [%d]\n" , rank, value); } while (value >= 0 ); MPI_Finalize(); return 0 ; }
或者可以使用 MPI_Send() 和 MPI_Recv() 来模拟 MPI_Bcast():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (rank == 0 ) { printf ("\n[进程%d] : 请输入需要广播的值 (小于0时, 程序退出)\n" , rank); scanf ("%d" , &value); int i; for (i=0 ; i<size; i++) { if (i != rank){ MPI_Send(&value, 1 , MPI_INT, i, 0 , MPI_COMM_WORLD); } } } else { MPI_Recv(&value, 1 , MPI_INT, 0 , 0 , MPI_COMM_WORLD, &status); printf ("[进程%d] : 收到来自 [进程0] 的广播, 接收数据为 [%d]\n" , rank, value); }
输出结果
1 2 3 4 5 [进程0] : 请输入需要广播的值 (小于0时, 程序退出) 10 [进程0] : 收到来自 [进程0] 的广播, 接收数据为 [10] [进程1] : 收到来自 [进程0] 的广播, 接收数据为 [10] [进程2] : 收到来自 [进程0] 的广播, 接收数据为 [10] [进程3] : 收到来自 [进程0] 的广播, 接收数据为 [10]
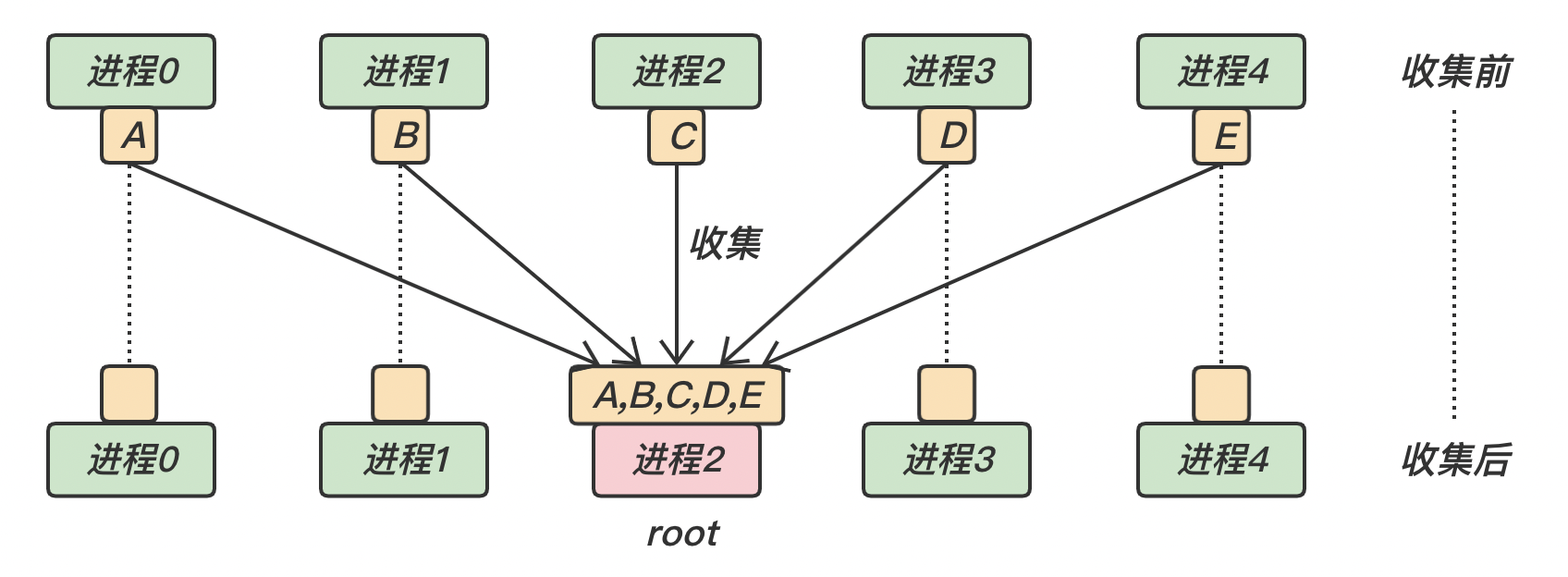
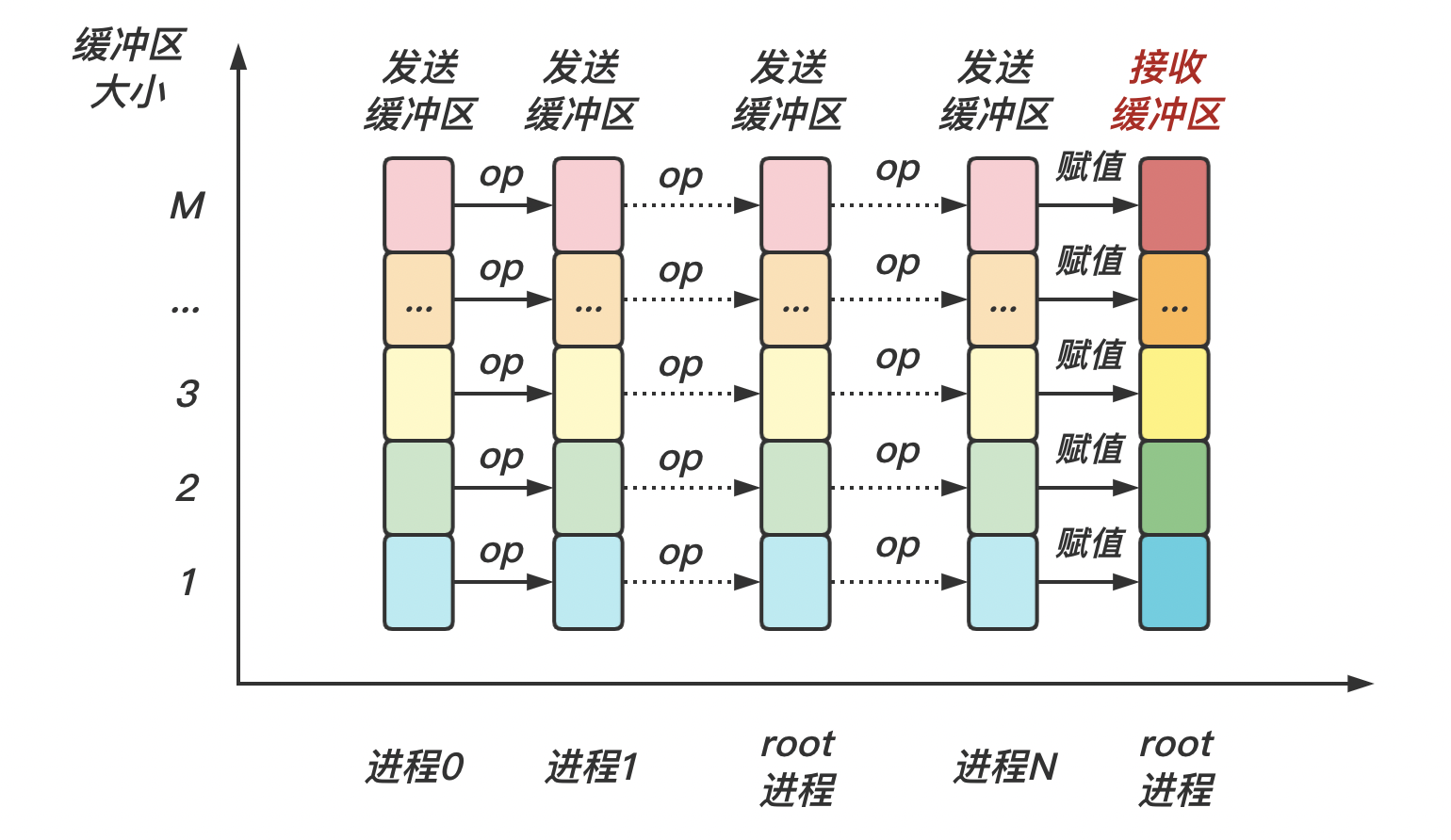
MPI_Gather通过 MPI_Gather 可以将其他进程中的数据收集到根进程。根进程接收这些消息,并把它们按照进程号 rank 的顺序进行存储。
对于所有非 root 进程,接收缓冲区会被忽略
在 MPI_Gather 调用中,发送数据的个数 sendcount 和发送数据的类型 sendtype 接收数据的个数 recvcount 和接受数据的类型 recvtype 要完全相同 MPI_Gather 的函数原型
1 2 3 4 5 6 7 8 9 10 int MPI_Gather ( void * sendbuf, int sendcount, MPI_Datatype sendtype, void * recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm ) ;
下面是 MPI_Gather 的示意图:对于所有进程,都执行一次发送;对于 root 进程,执行 n n n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <stdio.h> #include <stdlib.h> #include <mpi.h> void printRecvBuffer (int size, int recvBuffer[], int rank) ;int main (int argc, char *argv[]) { int value, rank, size; MPI_Status status; MPI_Request request; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); int recvBuffer[size]; value = rank; MPI_Gather(&value, 1 , MPI_INT, &recvBuffer[rank], 1 , MPI_INT, 0 , MPI_COMM_WORLD); printf ("[进程%d] : MPI_Gather(), 向 [进程0] 发送消息 [%d]\n" , rank, value); if (rank == 0 ) { printRecvBuffer(size, recvBuffer, rank); } MPI_Finalize(); return 0 ; } void printRecvBuffer (int size, int recvBuffer[], int rank) { printf ("[进程%d] : MPI_Gather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 " , rank); printf ("[ " ); for (int i=0 ; i<size; i++) { printf ("%d " , recvBuffer[i]); } printf ("]\n" ); }
输出结果
1 2 3 4 5 [进程1] : MPI_Gather(), 向 [进程0] 发送消息 [1] [进程3] : MPI_Gather(), 向 [进程0] 发送消息 [3] [进程2] : MPI_Gather(), 向 [进程0] 发送消息 [2] [进程0] : MPI_Gather(), 向 [进程0] 发送消息 [0] [进程0] : MPI_Gather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 [ 0 1 2 3 ]
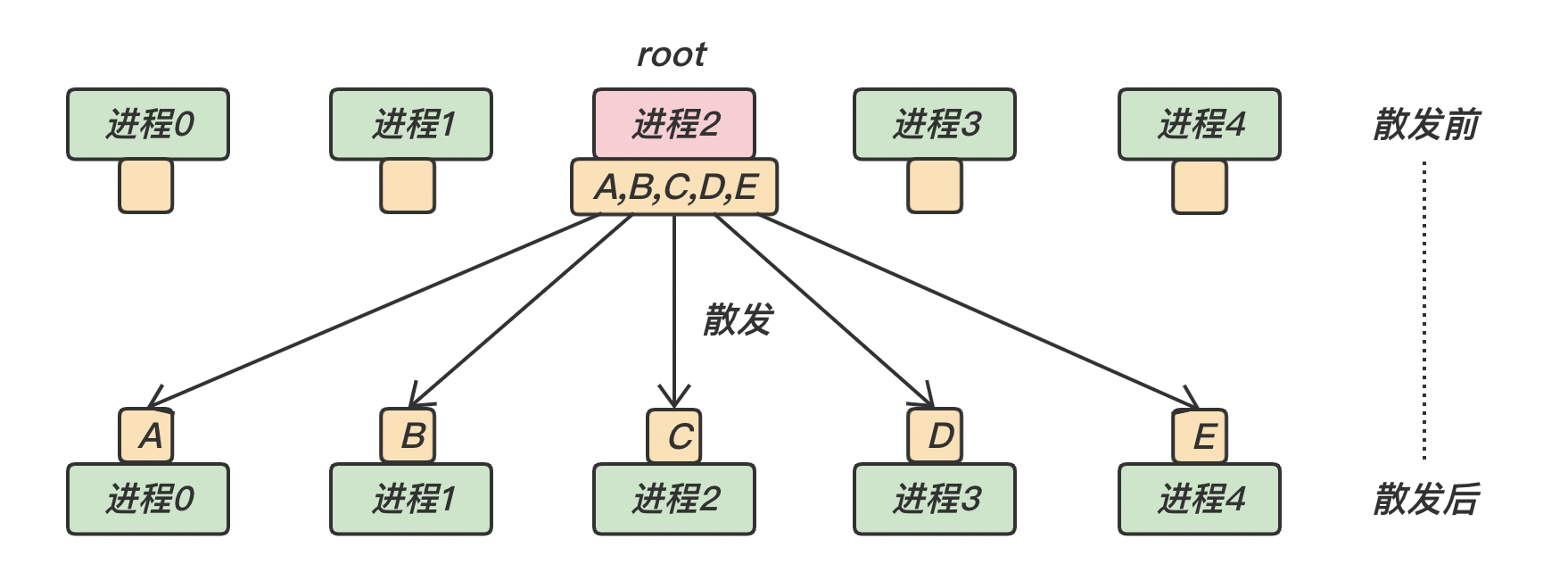
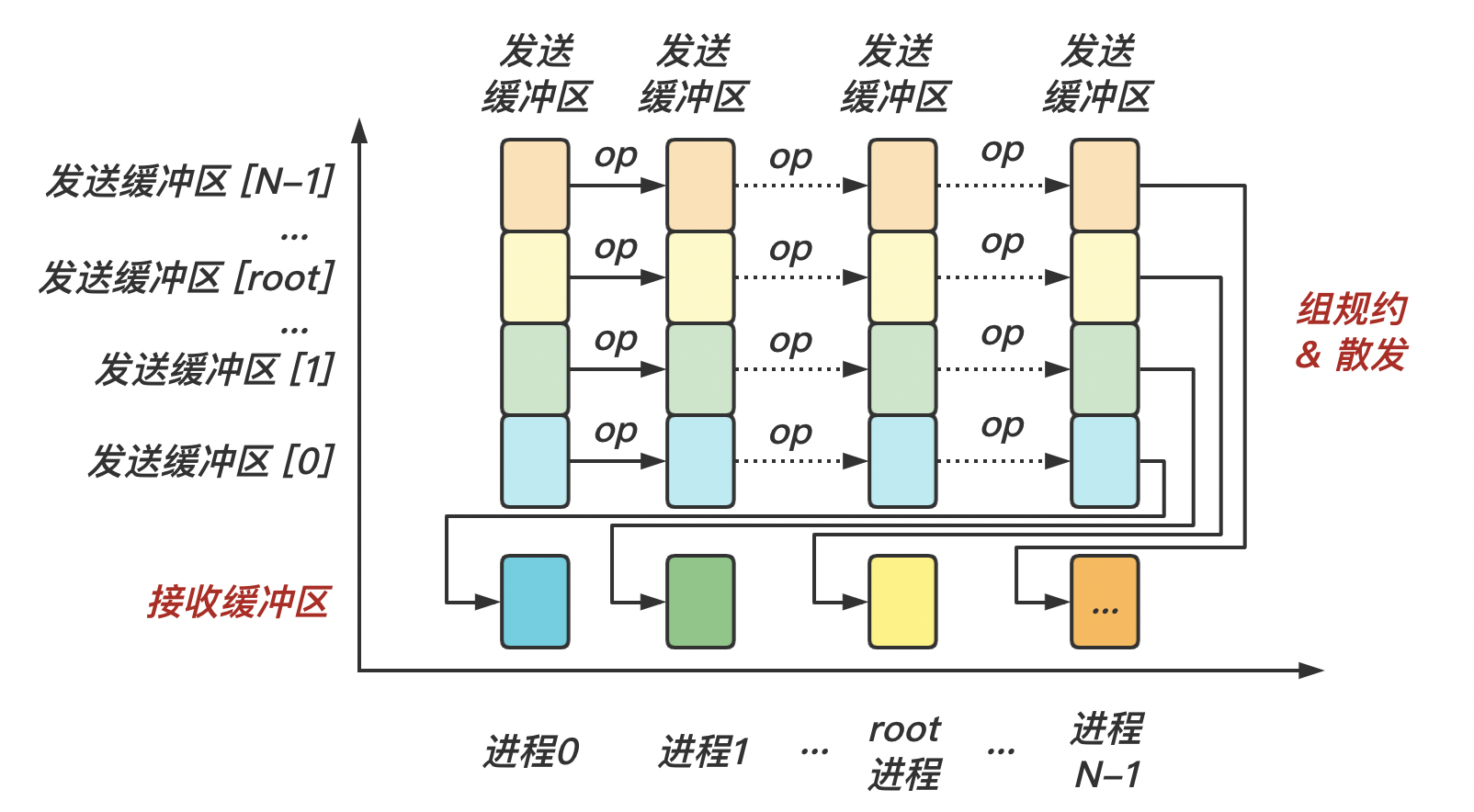
MPI_ScatterMPI_Scatter 是一对多的组通信调用,和广播不同的是,root 进程向各个进程发送的数据可以是不同的 MPI_Scatter 和 MPI_Gather 的效果正好相反,两者互为逆操作
对于所有非 root 进程,发送缓冲区会被忽略
相同的,在 MPI_Scatter 调用中,发送数据的个数 sendcount 和发送数据的类型 sendtype 接收数据的个数 recvcount 和接受数据的类型 recvtype 要完全相同 MPI_Scatter 的函数原型
1 2 3 4 5 6 7 8 9 10 int MPI_scatter ( void * sendbuf, int sendcount, MPI_Datatype sendtype, void * recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm ) ;
下面是 MPI_Scatter 的示意图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <stdio.h> #include <stdlib.h> #include <mpi.h> void printSendBuffer (int size, int sendBuffer[], int rank) ;int main (int argc, char *argv[]) { int value, rank, size; MPI_Status status; MPI_Request request; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); int sendBuffer[size]; if (rank == 0 ) { for (int i=0 ; i<size; i++) { sendBuffer[i] = i; } printSendBuffer(size, sendBuffer, rank); } MPI_Scatter(&sendBuffer[rank], 1 , MPI_INT, &value, 1 , MPI_INT, 0 , MPI_COMM_WORLD); printf ("[进程%d] : MPI_Scatter(), 从 [进程0] 接收消息 [%d]\n" , rank, value); MPI_Finalize(); return 0 ; } void printSendBuffer (int size, int sendBuffer[], int rank) { printf ("[进程%d] : MPI_Scatter(), 向 [所有进程] 散发消息, 发送缓冲区的数据为 " , rank); printf ("[ " ); for (int i=0 ; i<size; i++) { printf ("%d " , sendBuffer[i]); } printf ("]\n" ); }
输出结果
1 2 3 4 5 [进程0] : MPI_Scatter(), 向 [所有进程] 散发消息, 发送缓冲区的数据为 [ 0 1 2 3 ] [进程0] : MPI_Scatter(), 从 [进程0] 接收消息 [0] [进程3] : MPI_Scatter(), 从 [进程0] 接收消息 [3] [进程1] : MPI_Scatter(), 从 [进程0] 接收消息 [1] [进程2] : MPI_Scatter(), 从 [进程0] 接收消息 [2]
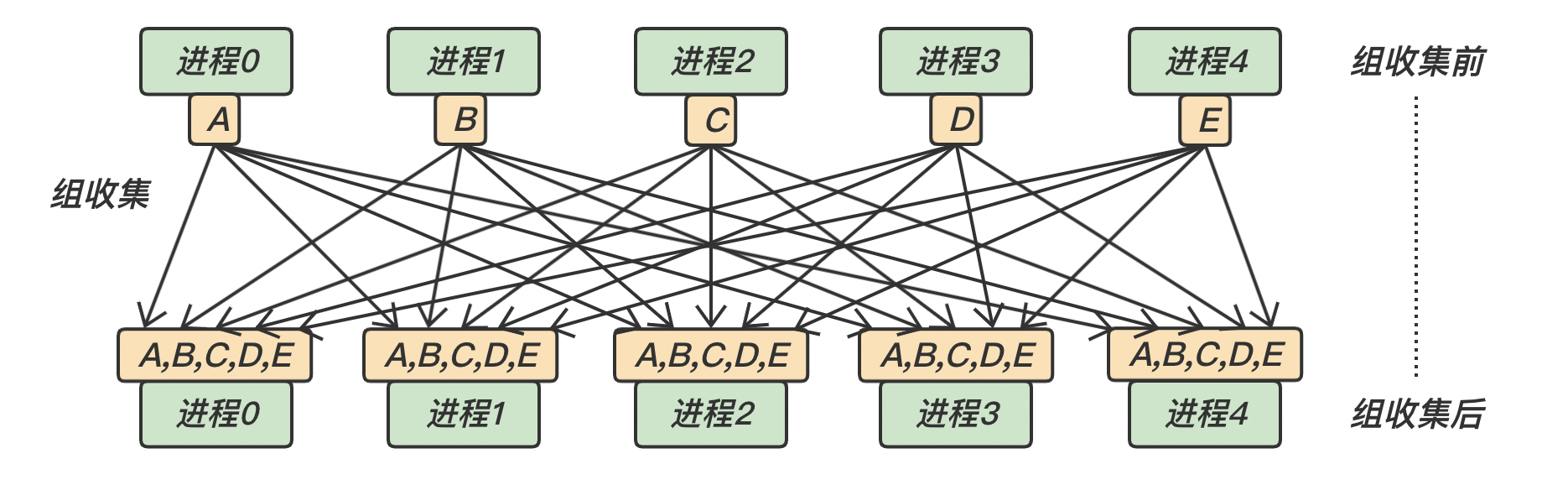
MPI_Allgather与 MPI_Gather 的区别:MPI_Gather 是将数据收集到 root 进程,而 MPI_Allgather 相当于每个进程都作为 root 进程执行了一次 MPI_Gather 调用 MPI_Allgather 的函数原型:
1 2 3 4 5 6 7 8 9 int MPI_Allgather ( void * sendbuf, int sendcount, MPI_Datatype sendtype, void * recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm ) ;
下面是 MPI_Allgather 的示意图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <stdlib.h> #include <mpi.h> void printRecvBuffer (int size, int recvBuffer[], int rank) ;int main (int argc, char *argv[]) { int value, rank, size; MPI_Status status; MPI_Request request; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); int recvBuffer[size]; value = rank; MPI_Allgather(&value, 1 , MPI_INT, &recvBuffer[0 ], 1 , MPI_INT, MPI_COMM_WORLD); printf ("[进程%d] : MPI_Allgather(), 向 [所有进程] 发送消息 [%d]\n" , rank, value); MPI_Finalize(); printRecvBuffer(size, recvBuffer, rank); return 0 ; } void printRecvBuffer (int size, int recvBuffer[], int rank) { printf ("[进程%d] : MPI_Allgather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 " , rank); printf ("[ " ); for (int i=0 ; i<size; i++) { printf ("%d " , recvBuffer[i]); } printf ("]\n" ); }
输出结果
1 2 3 4 5 6 7 8 [进程0] : MPI_Allgather(), 向 [所有进程] 发送消息 [0] [进程1] : MPI_Allgather(), 向 [所有进程] 发送消息 [1] [进程2] : MPI_Allgather(), 向 [所有进程] 发送消息 [2] [进程3] : MPI_Allgather(), 向 [所有进程] 发送消息 [3] [进程0] : MPI_Allgather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 [ 0 1 2 3 ] [进程1] : MPI_Allgather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 [ 0 1 2 3 ] [进程2] : MPI_Allgather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 [ 0 1 2 3 ] [进程3] : MPI_Allgather(), 从 [所有进程] 收集消息, 接收缓冲区的数据为 [ 0 1 2 3 ]
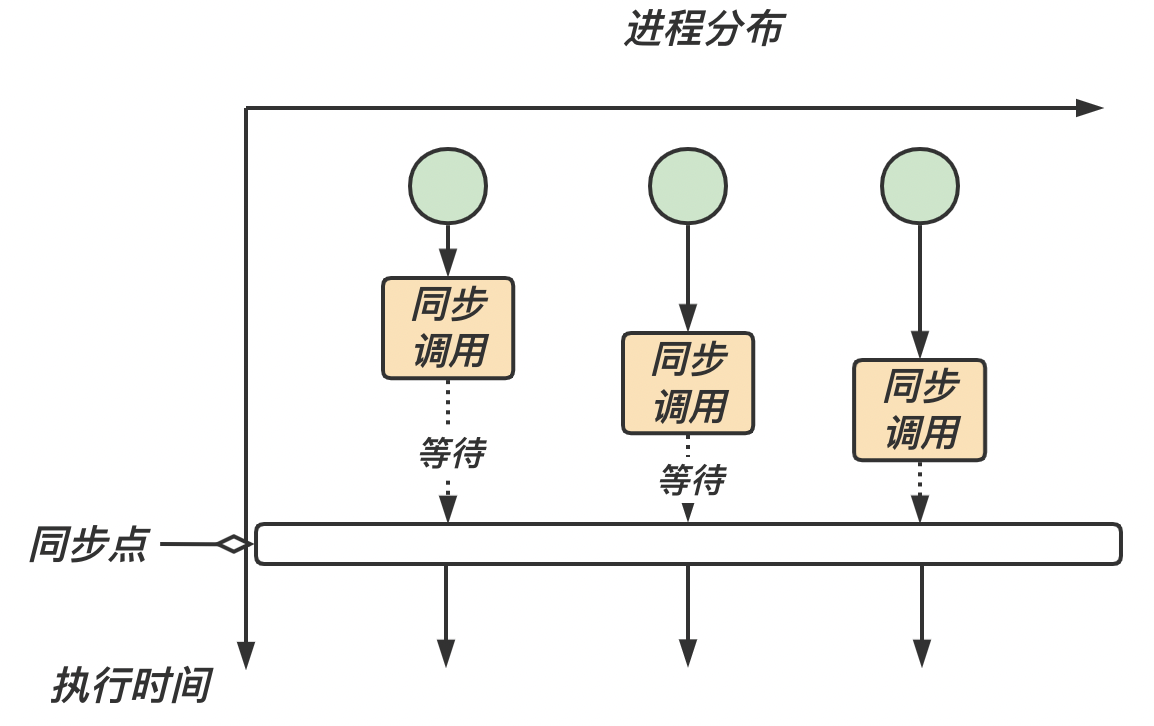
我们知道,每个进程的运行速度是不同的。如果我们需要每个进程的运行进度,组通信提供了专门的调用以完成各个进程之间的同步,从而协调各个进程的进度和步伐
等到所有进程的进度都到达同步点 同步
MPI_Barrier在 MPI 中,我们称这个同步点为 MPI_Barrier。MPI_Barrier 会阻塞进程,直到组中的所有成员都调用了它,组中的进程才会往下执行。
下面是 MPI_Barrier 的函数原型:
1 int MPI_Barrier ( MPI_Comm communicator ) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <stdio.h> #include <stdlib.h> #include <mpi.h> #include <unistd.h> #include <time.h> void printRecvBuffer (int size, int recvBuffer[], int rank) ;int main (int argc, char *argv[]) { int value, rank, size; MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); time_t startTime, endTime; startTime=time(NULL ); switch (rank){ case 0 : sleep(3 ); break ; case 1 : sleep(2 ); break ; case 2 : sleep(1 ); break ; default : break ; } MPI_Barrier(MPI_COMM_WORLD); endTime=time(NULL ); printf ("[进程%d] : MPI_Barrier(). 执行时常为[%ld]秒.\n" , rank, (endTime-startTime)); MPI_Finalize(); return 0 ; }
输出结果
1 2 3 4 [进程1] : MPI_Barrier(). 执行时常为[3]秒. [进程3] : MPI_Barrier(). 执行时常为[3]秒. [进程2] : MPI_Barrier(). 执行时常为[3]秒. [进程0] : MPI_Barrier(). 执行时常为[3]秒.
MPI 组通信提供了计算功能的调用,通过这些调用可以对接收到的数据进行处理。当消息传递完毕后,组通信会用给定的计算操作对接收到的数据进行处理,处理完毕后将结果放入指定的接收缓冲区。即分为三个部分:(1)组内消息通信;(2)对接收到的数据进行处理,如规约等;(3)结果放入接收缓冲区。
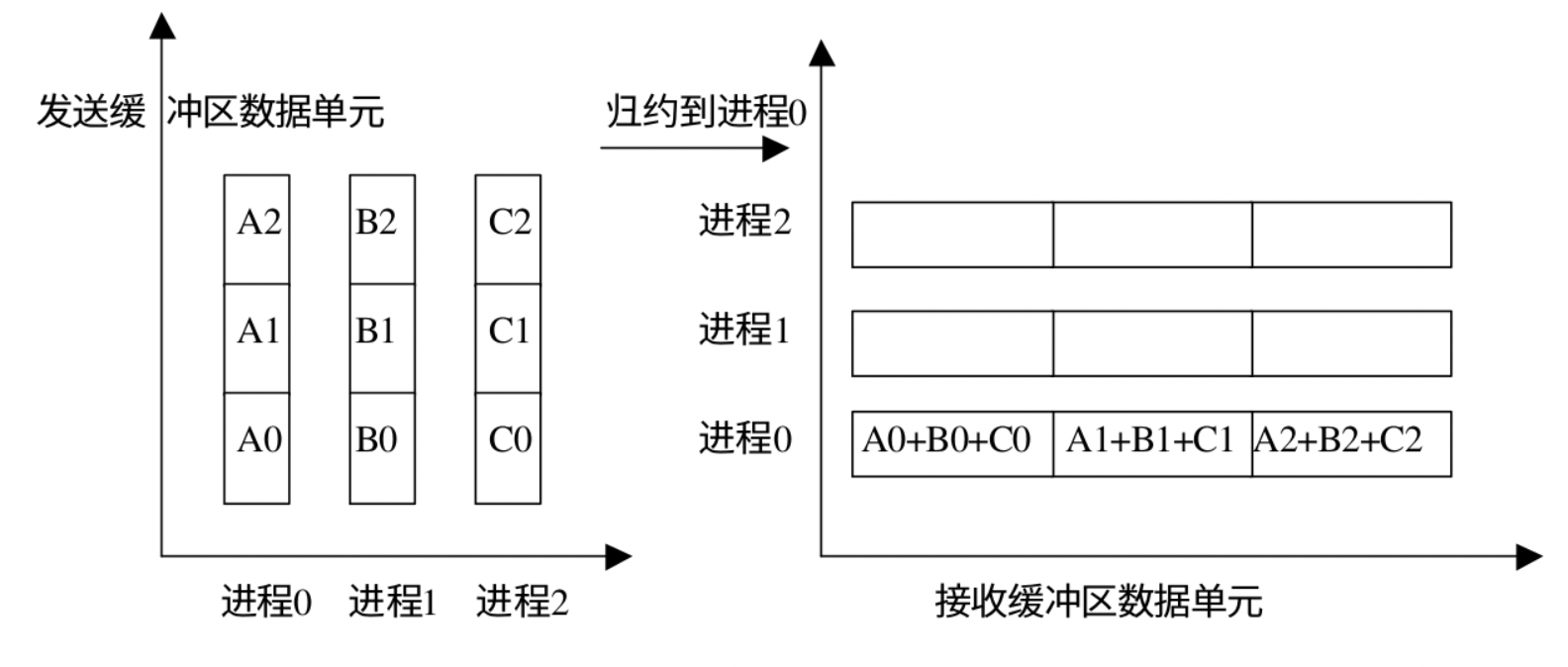
MPI_ReduceMPI_Reduce 用来将组内每个进程发送缓冲区 操作 op 进行运算 结果返回到序号为 root 的接收缓冲区 op 始终被认为是可以结合的,并且所有 MPI 定义的操作被认为是可交换的。用户自定义的操作被认为是可结合的,但是可以不是可交换的。
下面是 MPI_Reduce 的示意图:
下面是 MPI_Reduce 的函数原型:
1 2 3 4 5 6 7 8 9 int MPI_Reduce ( void * sendbuf, void * recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm ) ;
MPI 预定义了一些规约操作 MPI_Op,如下表所示:
操作
含义
MPI_MAX最大值
MPI_MIN最小值
MPI_SUM求和
MPI_PROD求积
MPI_LAND逻辑与
MPI_BAND按位与
MPI_LOR逻辑或
MPI_BOR按位或
MPI_LXOR逻辑异或
MPI_BXOR按位异或
MPI_MAXLOC最大值且相应位置
MPI_MINLOC最小值且相应位置
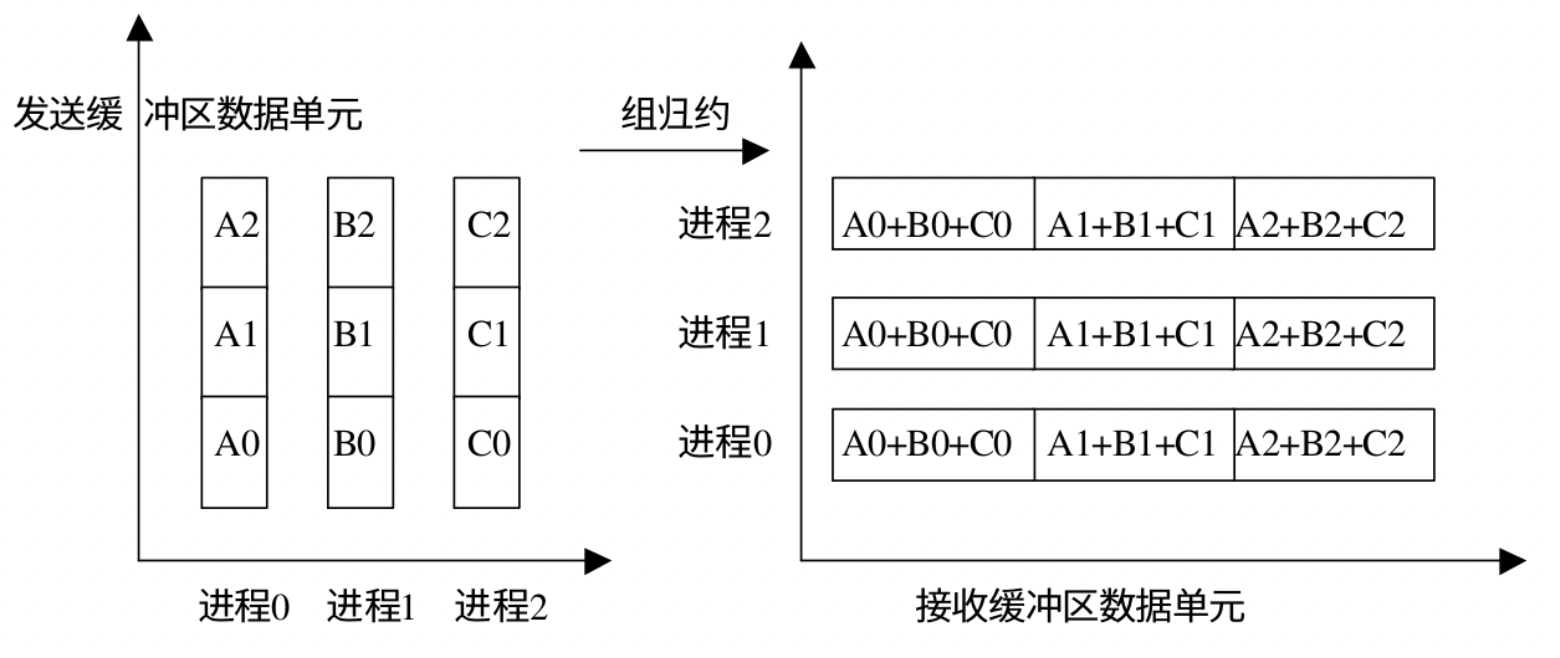
MPI_Allreduce组规约 MPI_Allreduce 相当于组中每个进程作为 root 进行了一次规约操作 每个进程都有规约的结果
下面是 MPI_Allreduce 的函数原型:
1 2 3 4 5 6 7 8 int MPI_Allreduce ( void * sendbuf, void * recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm ) ;
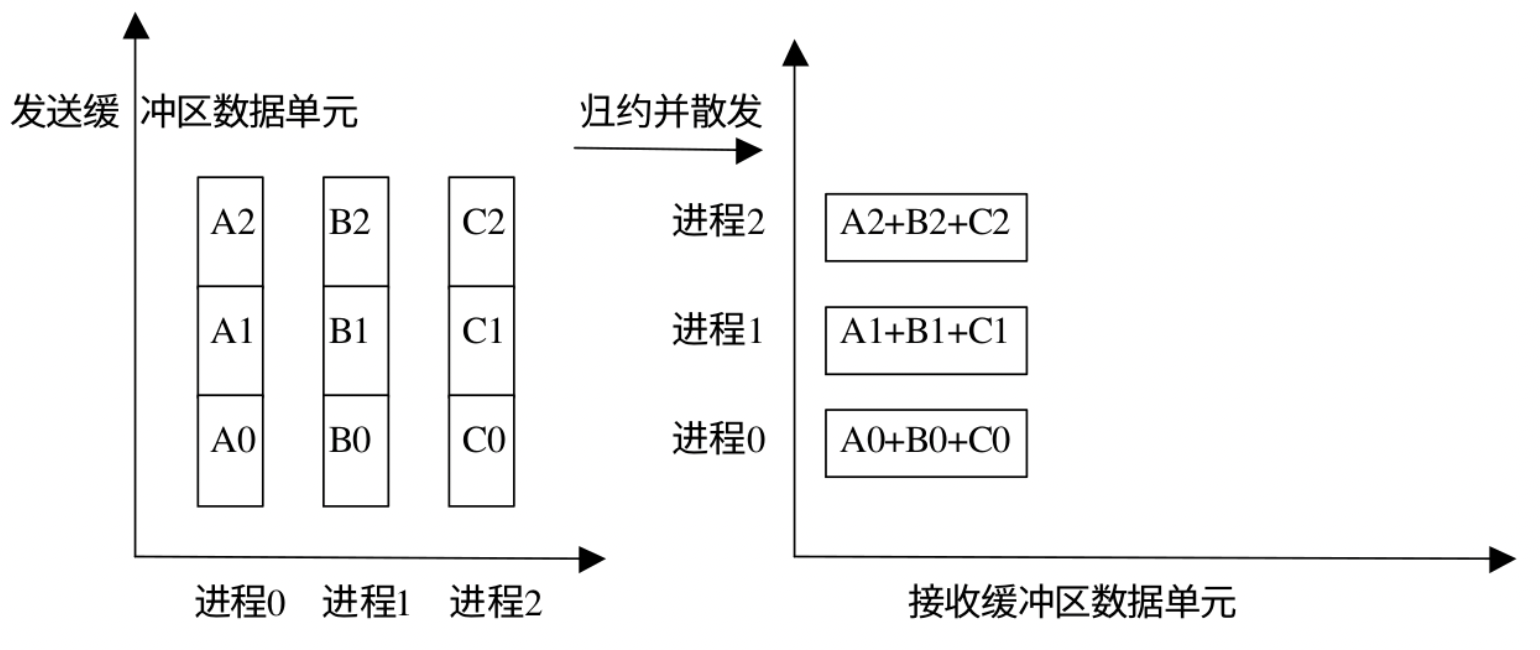
MPI_Reduce_scatterMPI_Reduce_scatter 会将规约结果分散到组内的所有进程中去 MPI_Reduce_scatter 中,发送数据的长度要大于接收数据的长度,这样才可以把规约的一部分结果散射到各个进程中。该函数的参数中有个 recvcounts 数组,用来记录每个进程结束数据的数量,这个数组元素的和就是发送数据的长度。
下面是示意图:
下面是函数原型:
1 2 3 4 5 6 7 8 int MPI_Reduce_scatter ( void * sendbuf, void * recvbuf, int * recvcounts, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm ) ;
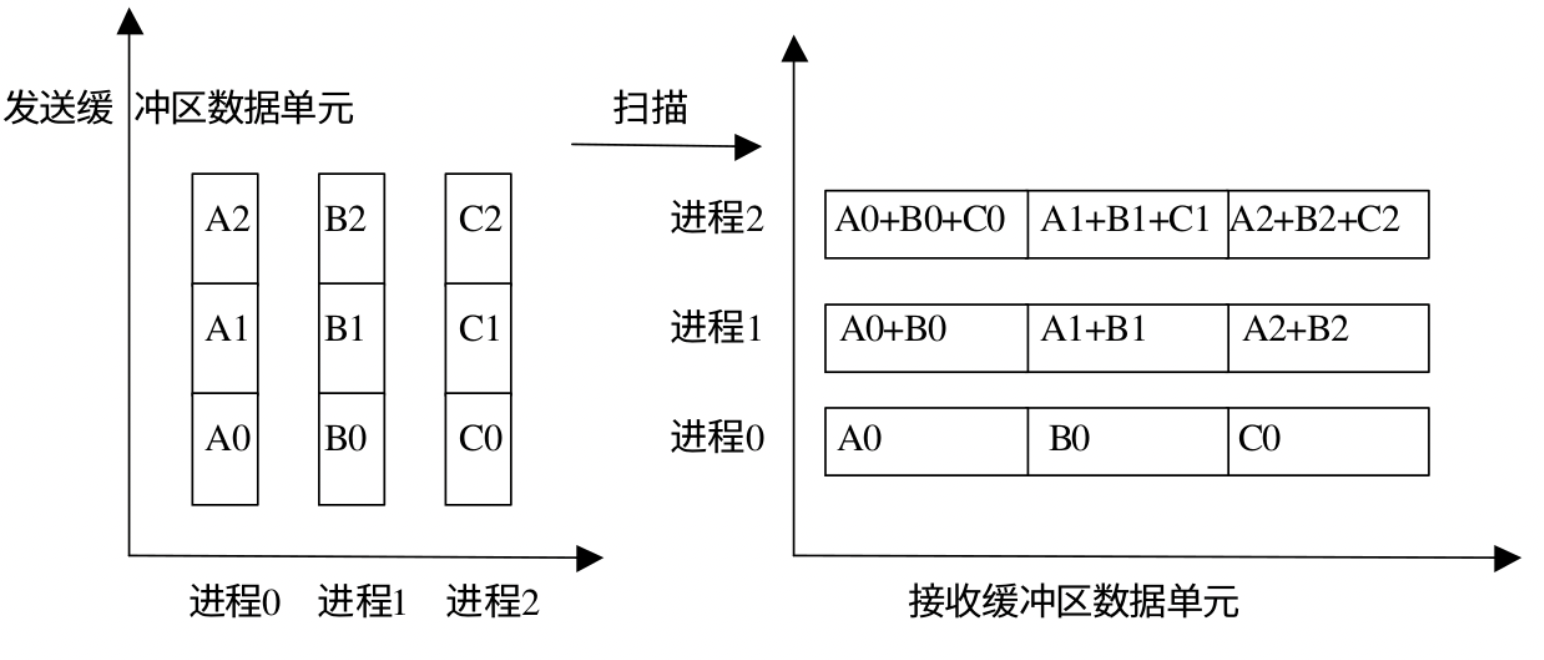
MPI_Scan可以将扫面看做是一种特殊的规约,即每个进程都对排在它前面的进程进行规约操作。 MPI_Scan 的调用结果是,对于每一个进程 i i i 0 , . . . , i 0,...,i 0 , . . . , i i i i
下面是 MPI_Scan 的函数原型:
1 2 3 4 5 6 7 8 int MPI_Reduce ( void * sendbuf, void * recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm ) ;
下面是不同的规约操作的数据变化:我们规定 MPI_Op 为 MPI_SUM,在进程0,进程1 和进程2 之间不同的规约操作:
MPI_Reduce:
MPI_Allreduce :
MPI_Reduce_scatter :
MPI_Scan :