写在前面:
本文章是根据法国国立高等电力技术、电子学、计算机、水力学与电信学校 (E.N.S.E.E.I.H.T.) 第九学期课程 “Web Semantic” 及以下参考资料总结而来的课程笔记。碍于本人学识有限,部分叙述难免存在纰漏,请读者注意甄别。
参考:
- 《知识工程及语义网技术》- 胡伟教授(南京大学)
- 课程视频资料:哔哩哔哩 - 个人主页:奋进的胡人Leo
- 教学课件
- 《语义网基础教程》- 第三版(机械工业出版社)
一、万维网与语义网,本体语言
0 引例
我们首先观察如下一个例子:
我们在搜索引擎搜索关键字 “Shiing-Shen Chern” 时,可以看到如下搜索结果。左边是传统的搜索结果,每一个结果都是一个页面;而在页面的右边,则是一个叫“知识卡片 (Knowledge Card)”的新特性。在知识卡片中给出了一些关于搜索结果的结构化的数据,如出生信息等。
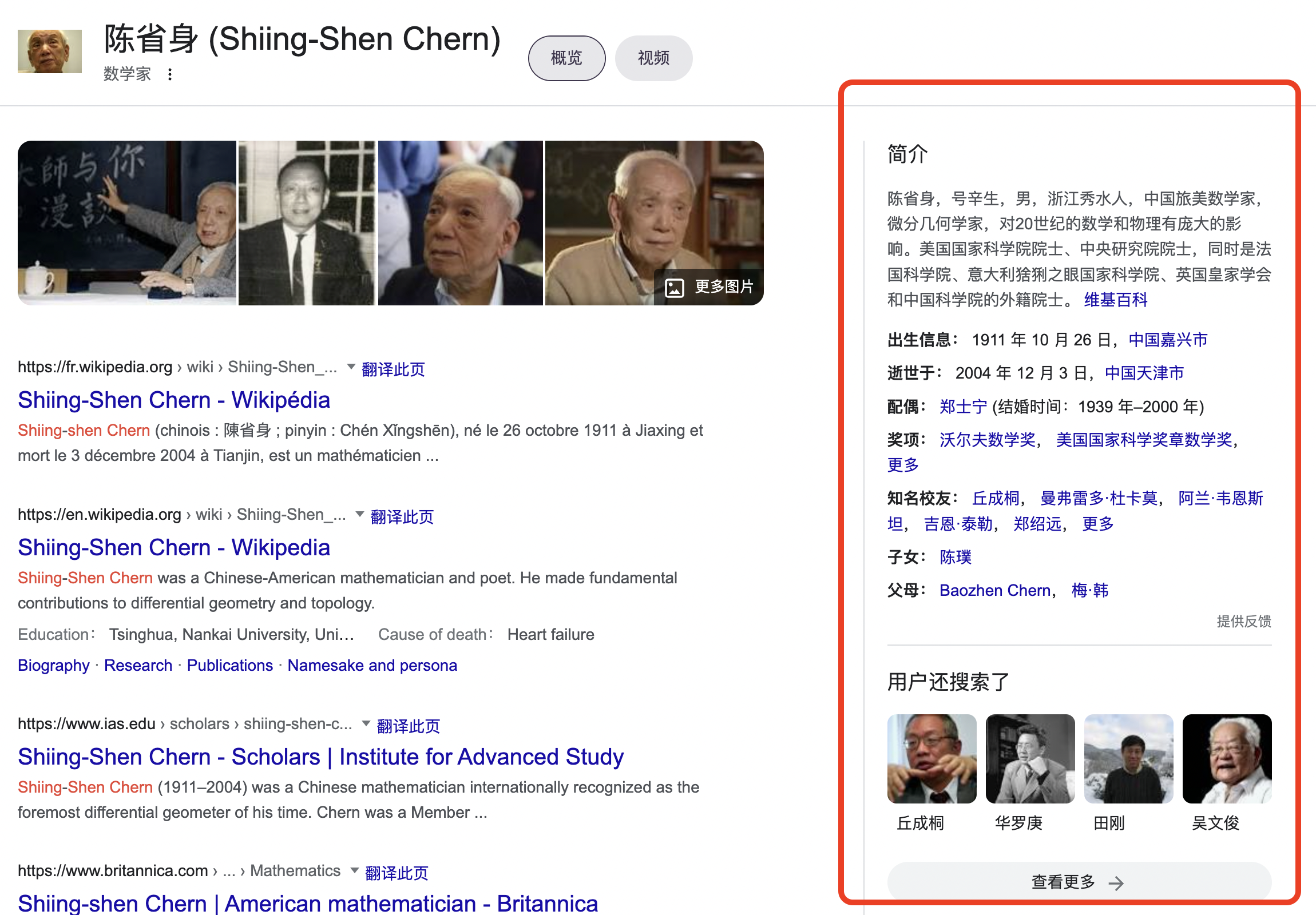
从以上这个例子中我们看出,如今万维网搜索的新趋势不仅仅是寻找一个 Web 页面,而是寻求答案,理解概念并进行探索。在这种背景下,万维网该如何理解真实世界的事务,以及事物件的练习呢?
谷歌提出了“知识图谱 (Knowledge Graph) ”的概念,以更好的提供结构化的搜索结果。在这种结构化的结果背后,是关于世界上“人”、“地点”和“事物”的巨大集合,以及他们之间的关联。
1 万维网
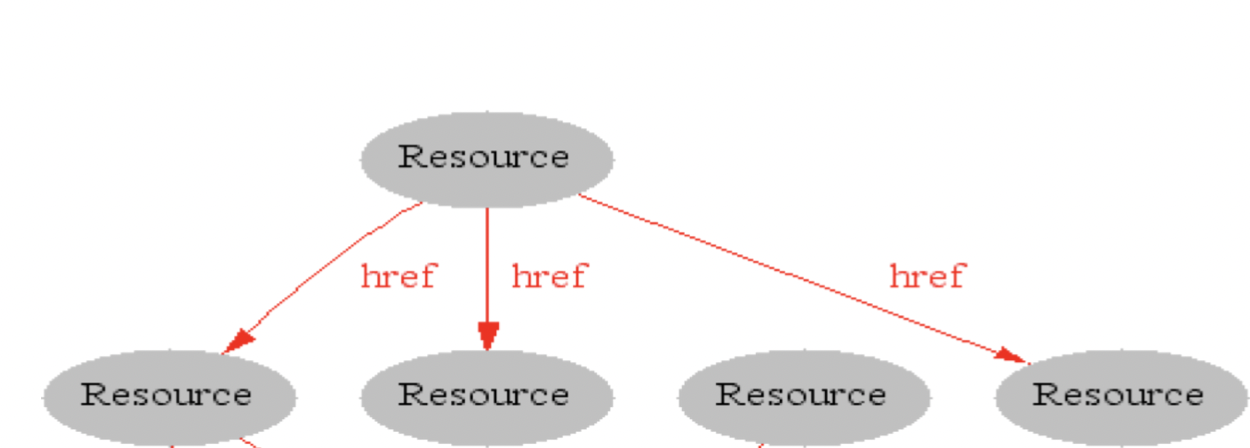
万维网(World Wide Web)是一个透过互联网访问的,由许多互相链接的超文本组成的资讯系统。资源 Resource 之间通过有向的超链接 href 连接:
英国科学家 Tim Berners-Lee 于 1989 年发明了万维网。他发明了三项关键技术:
- 一个全球网络资源唯一认证的系统,统一资源标志符(URI);
- 超文本标记语言(HTML);
- 超文本传输协议(HTTP)
随着发展,资源爆炸式增加,单纯的超连接已经不能满足对资源的访问(包括黄页)。搜索引擎应运而生。
Web 1.0
在 Web 1.0 的体系中,普通用户作为 Web 内容的消费者,通过访问 Web 内容(静态网页或动态网页)亦或通过 Web 应用访问 Web 服务。
Web 1.0
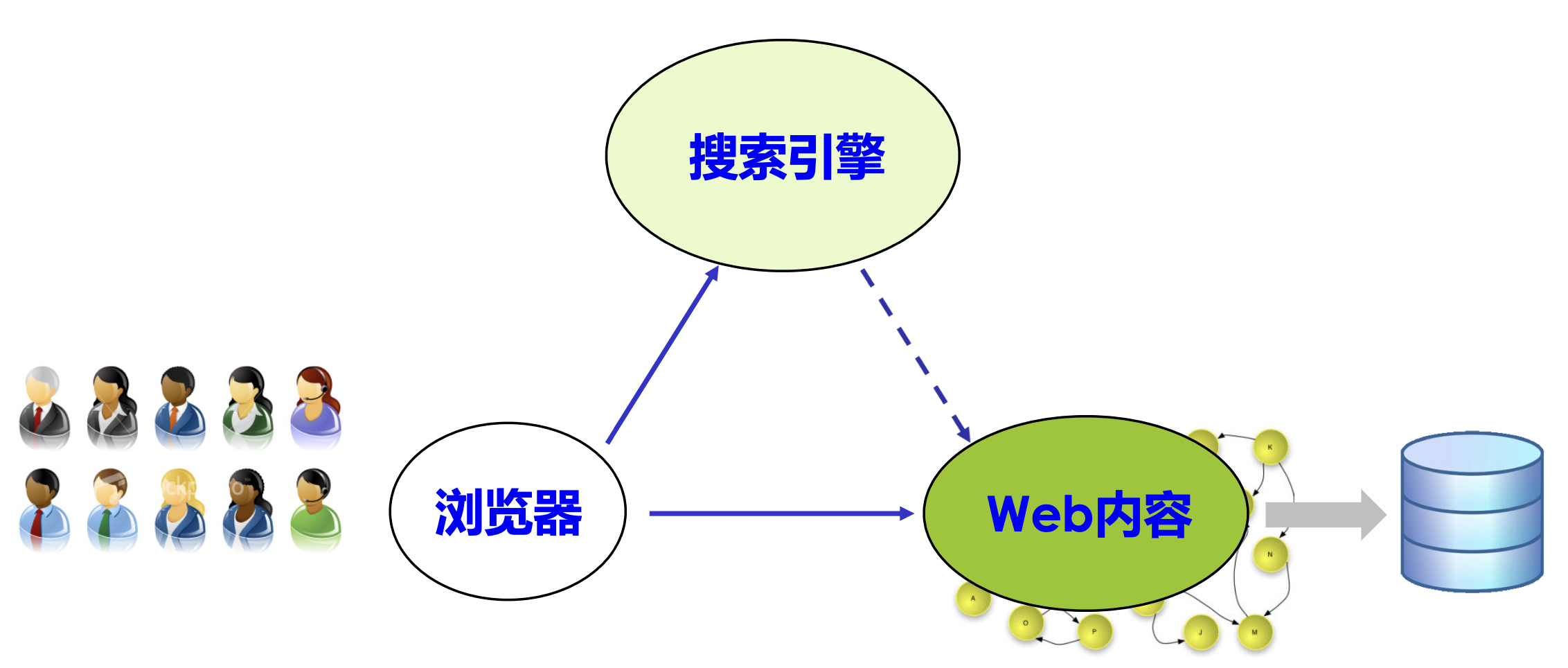
Web 1.x
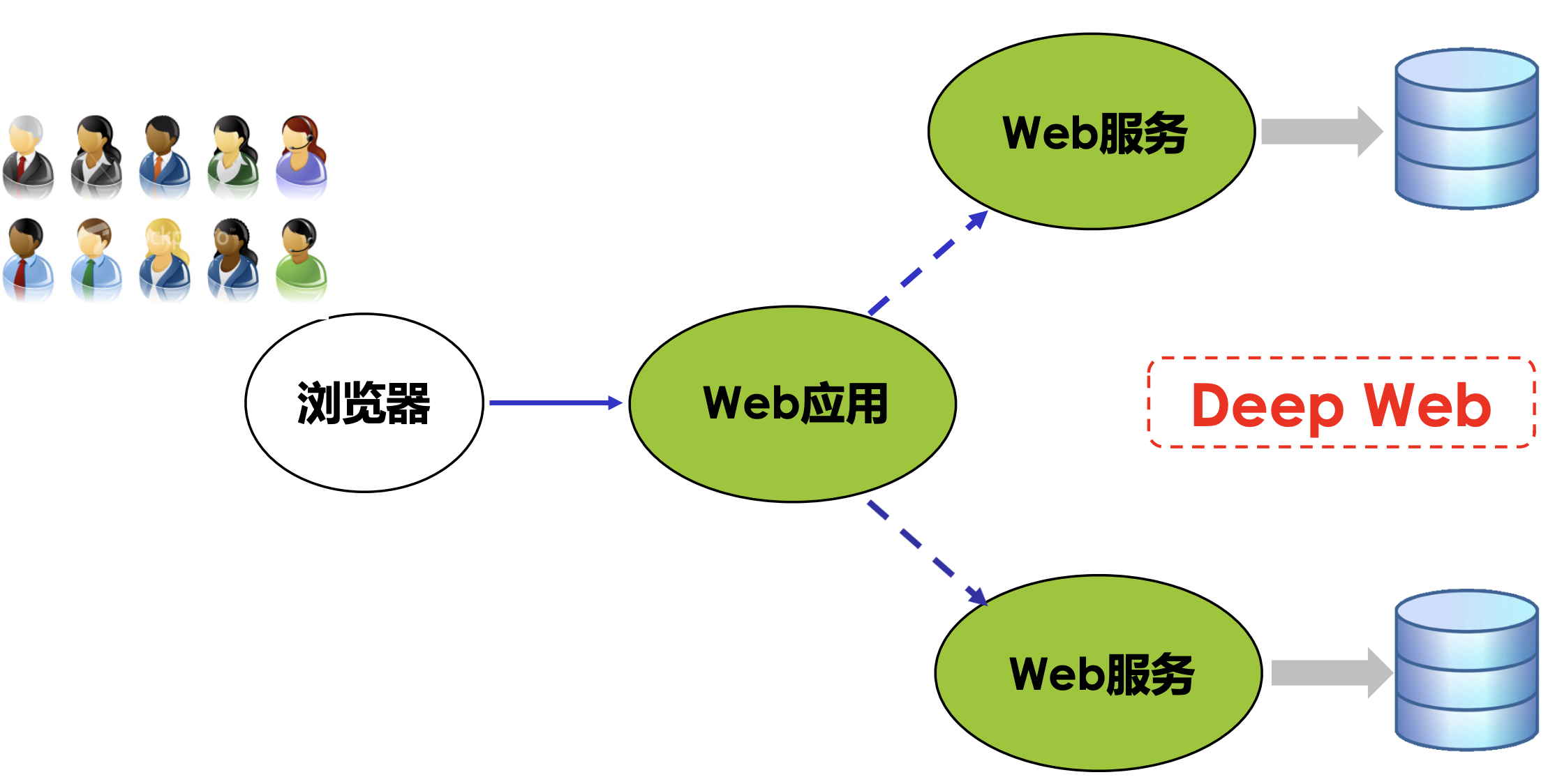
Web 2.0
在 Web 2.0 体系中,普通用户作为 Web 内容的生产者和消费者,既在 Web 上生产内容,同时也消费内容(如博客,百科词条等)。
但是在这其中,始终都是人作为 Web 的主导者,由人生产和消费 Web 内容,只有人才能懂得 Web 上的内容。计算机并无法搞懂 Web 中的内容。所以在这样的背景下,出现了语义网的概念。
2 语义网
语义网(Semantic Web)是由万维网联盟的 Tim Berners-Lee 在 1998 年提出的一个概念,它的核心是:通过给万维网上的文档(如: HTML文档)添加能够被计算机所理解的语义(元数据),从而使整个互联网成为一个通用的信息交换介质。
如今万维网的内容绝大多数都是由数据库提供,我们可以直接在数据层面将其相互关联,使其能够被计算机所理解。而 RDF 则是实现语义网的一种数据结构。
语义网层次结构
语义网实质上是多种现存技术结合构成的有机整体。
Berners-Lee 提出语义网这个技术概念时,XML 技术已经在网络上大行其道;RDF 开始初露端倪;本体技术、逻辑语义在知识工程领域已经有几十年的研究历史。但正是 Berners-Lee 将这些技术的应用结合起来,设计出了语义网的技术层次架构图。其是应用最多的关于语义网结构的层次模型,或称协议栈(Protocal Stakes)。
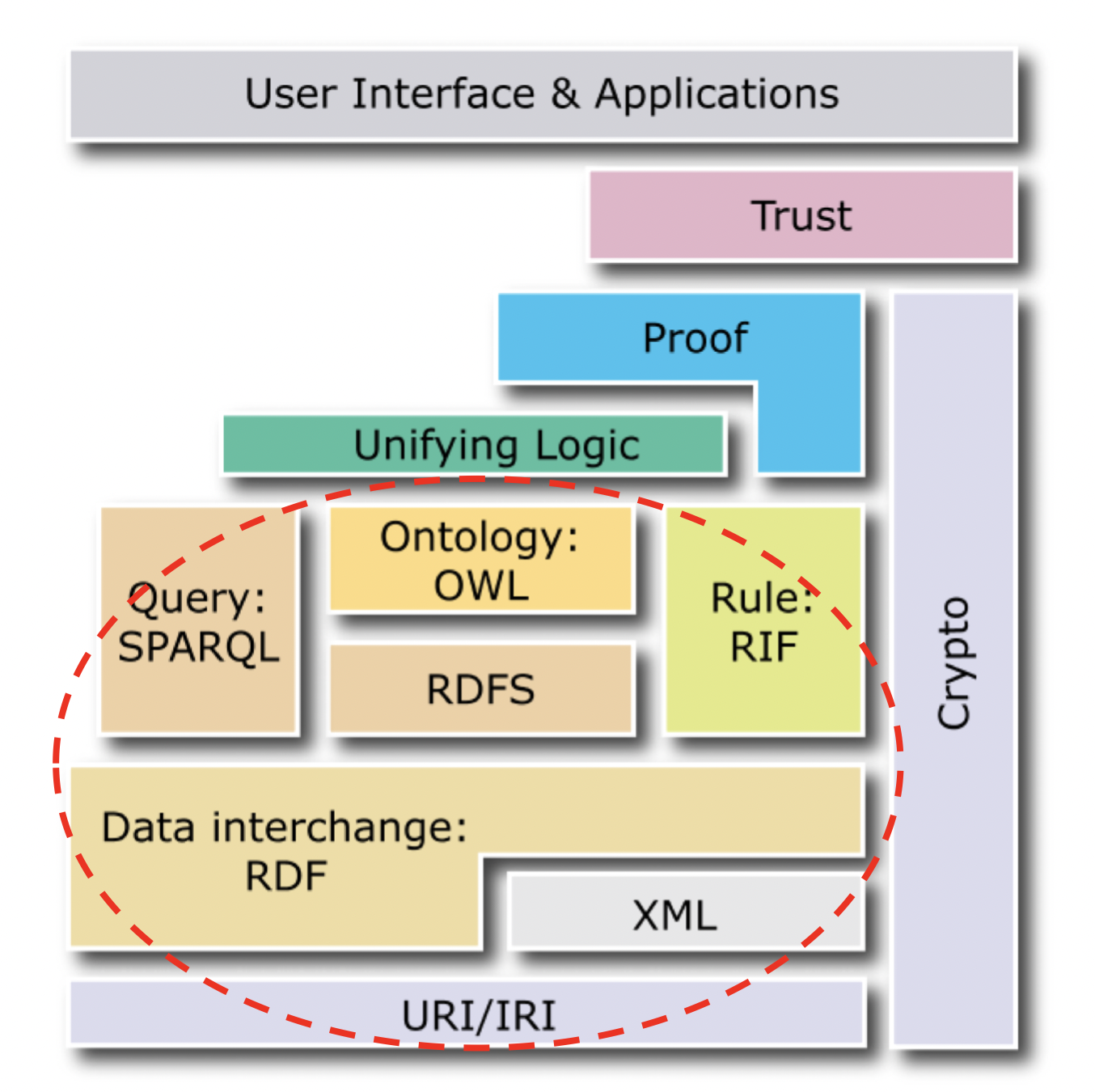
第一层:URI/IRI
URI(统一资源标识符)是当前 Web 上用来标识资源的一种方式,但是只能使用 ASCII 字符集中的有限字符标识资源。因此有了 IRI(国际化资源标识符)即 URI 的国际化版本,允许使用所有 Unicode 字符标识资源,方便非英语国家和地区的使用。
语义网中所有被描述的事物都称为资源,采用 URI/IRI 进行唯一表示。
URI 包含三部分,统一命名规则分配体系,资源宿主机器的名称、以路径的形式给出的资源名称。
URI包括统一资源名称(URN)和统一资源定位器(URL)。URL 需要指明资源所在的位置和存取方式;URN 要求是全球唯一的,不需要指明位置,并且在资源不存在或者不可用的时候依然保持不变。
第二层:XML(句法层)
句法层的核心是 XML 及其相关规范,主要包括 XML、NS 和 XML Schema。
- XML 是当前 Web 上表示结构化文档和数据的一种规范语言,具有结构化、平台无关、易扩展、可伸缩的特性,被广泛用于网络信息描述和交换。
- NS 是命名空间,一种在多数据源环境下避免名称冲突的方式,由 URI 标识符决定,能够明确表示 XML 文档中来自不同词汇表的元素和属性,有效地保证了资源标识的唯一性。
- XML Schema 是定义 XML 文档中元素、属性、数据类型及文档结构的一种方式,提供了 XML 文档的校验机制,保证了XML文档的完整性、有效性和一致性。
这一层提供了语义网的句法基础和编码方式,使网络资源的表现形式、数据结构和内容能够分离。
第三层:RDF(资源描述框架)
- RDF 是语义网中用于资源描述的框架,由“主-谓-宾 ”三元组的形式组成。
- 在 RDF 中描述资源所需的词汇,需要预先在本体中定义。
- RDF 是语义网的基石,它所表达的信息主要面向应用程序处理,或者说它提供了一种机器可读可理解的资源描述格式。
- RDF 有多种序列化格式,其中XML类型的序列化是面向机器阅读和处理的格式。
第四层:本体
第三层中提到,RDF 描述资源所需的词汇,需要预先在本体中定义,那么这里的本体就是第四层的内容。
- Ontology 本体是语义网的核心,其本质是一种共享词表,是对一个领域内一组概念及其概念间相互关系的形式化表达,为语义网提供了语义。
- RDFS 是一种轻量级的本体,提供了定义和描述 RDF 词汇的框架,但是 RDFS 的表达能力较弱,而且不具备推理能力。
- OWL 弥补了 RDFS 的不足,是一种高级本体语言,能够描述事物间复杂的关系。而且 OWL 建立在描述逻辑的基础之上,为语义网带来了推理能力。
- SPARQL,为了查询 RDF 数据,W3C 定义了一种简单协议和 RDF 查询语言,即 SPARQL,这是一种类似 SQL 的语言。
- RIF:规则交换格式。是一种把基于规则的技术引入语义网知识表示的方法,可以提高本体的描述能力,增强信息的语义表达能力。
第七、八、九层
剩下三层是目前尚未实现的语义网技术
- 第五层:逻辑层提供公理和推理规则,为智能推理提供基础。
- 第六层:证明层提供认证机制,执行逻辑层产生的规则。
- 第七层:信任层提供信任机制,保证资源的交互安全可靠。
- 最后是用户界面,使人类用户能够对语义网应用程序进行访问和交互。
3 本体工程
3.1 本体的粗略概念
本体源自哲学之中称为“形而上学”的分支。形而上学所关注的是现实的本质,也就是存在的本质。作为哲学的一个基本分支,形而上学关注的是分析存在的各种类型或模式。研究“存在”以及他们的基本分类。
在计算机科学中,本体是一个工程概念。
一个本体是一个(共享)概念化的一种(形式化的显性)规约。
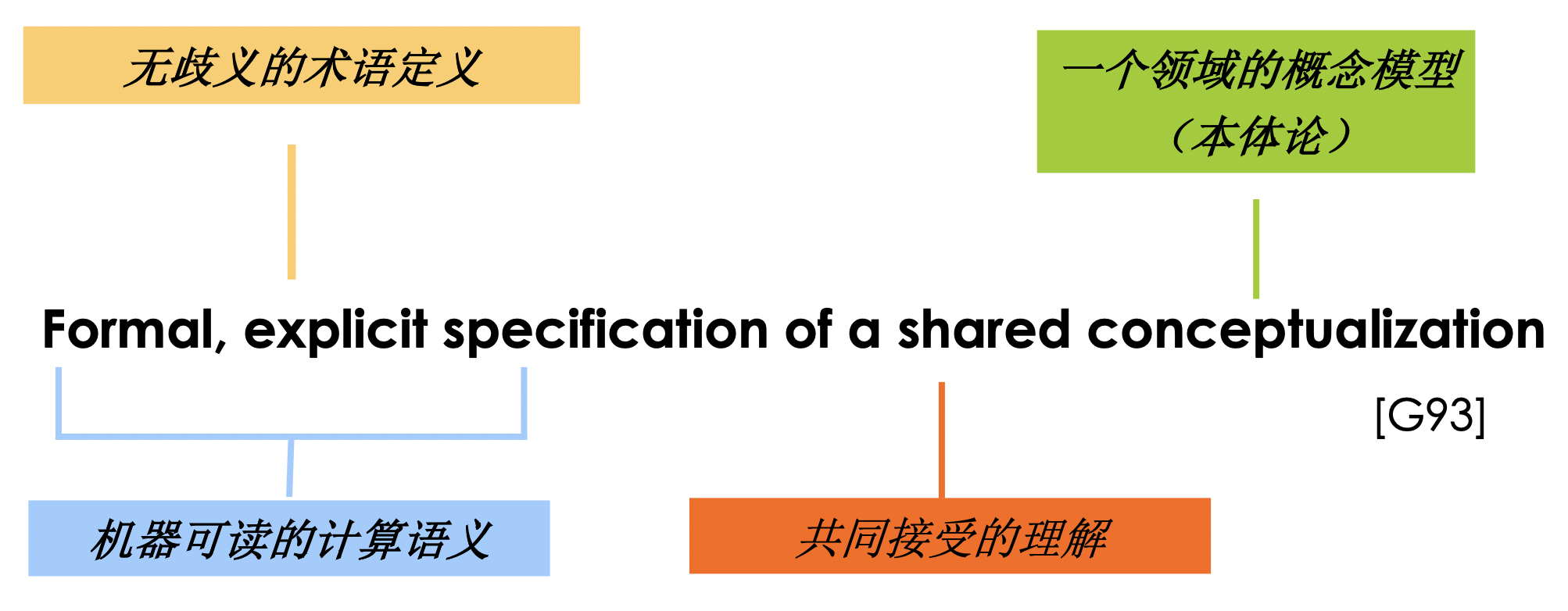
其中包括:
- 一个词汇集,用于描述某个领域的一个特殊视角;
- 词汇集含义的显示说明,经常包含基于分类的信息
- 例如,定义大象是一种动物。食草动物是一类只吃植物的动物
- 约束,用户捕获关于领域的背景知识
- 例如,一种动物的实例不能既是食草动物又是食肉动物
在一个理想情况下,一个本体应当:
- (人)捕获一个共同兴趣领域内的共享理解
- (机器)提供一个形式化的、机器可操作的模型
3.2 一个本体的实例
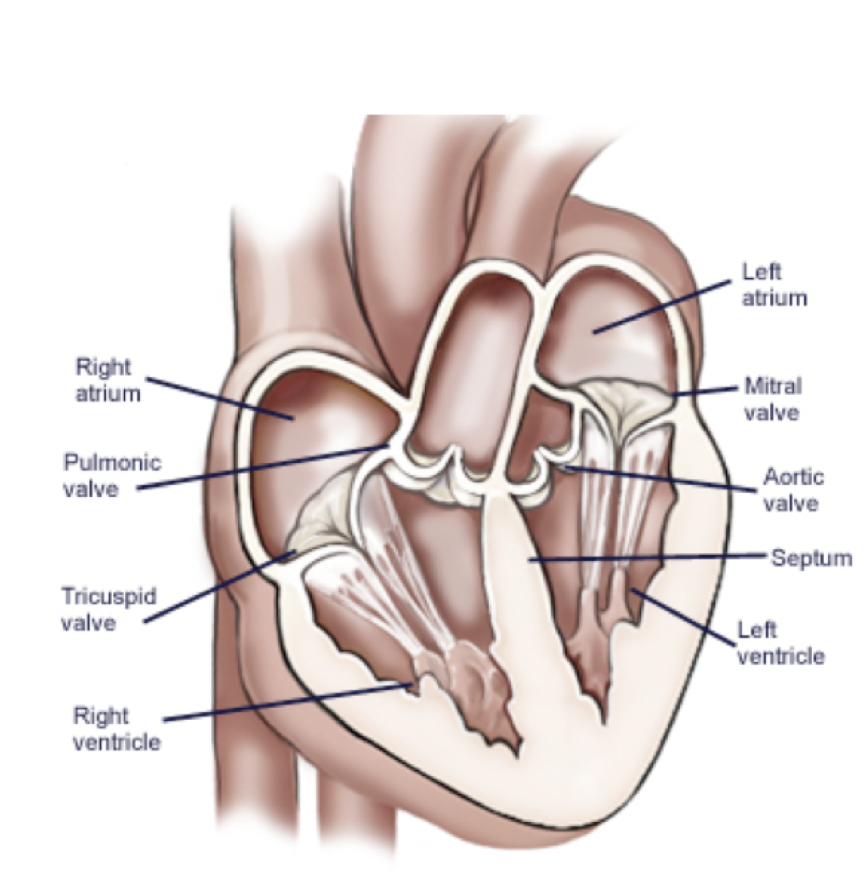
对于上图这样一个心脏,我们首先对其创建一个模型:
-
引入领域相关的词汇集
-
指定术语的含义(语义):心脏是循环系统中的一个肌肉组织
-
使用合适的描述逻辑来形式化:
描述逻辑
描述逻辑的知识库包括两个部分:
-
本体公理(
axiom,也叫做 TBox)定义术语(模型) -
本体事实(
fact,也叫做 ABox)使用术语(数据实例)
3.3 本体工程
本体工程关注的是本体开发过程、本体生命周期、用于构建本体的方法和方法学,以及那些勇于支持这些方面的语言和工具。
二、XML
2.1 什么是 XML
XML 指可扩展标记语言(eXtensible Markup Language)。XML 建立了一套指令,用于以机器和人类可读的方式对文本进行格式化。XML 是一种流行的数据存储格式,被广泛用于在互联网上交换信息。
XML 文档是由元素组成的,这些元素可以包含文本、其他元素或两者。元素由开始和结束标签来划分,用角括号括起来。
2.2 XML 的特点
- 可以用于电子数据的交换
- 开发灵活
- 因为 XML 是数据与格式分离设计的,所以 XML 元数据文件就是纯数据文件。这样就可以使用同一个数据源,显示多种样式。而使用 HTML 的话,每显示一种样式,就必须重新把数据与格式但在一起(设计时)。
- XML 采用的标签 (tag) 是自定义的,可以大大提高数据的可读性。
- 面向对象的特性:XML 文件是以树状方式存储的,同时具有属性,这很符合面向对象方式的编程。
2.3 XML 的语法格式
XML 声明
1 | <!-- 文档声明必须写在第一行 version为必须属性 --> |
XML 数据文件不能像 HTML 那样自由,他是非常严格的。每个 XML 解析器的第一步就是要检查 XML 文件的格式。所以声明必须写在第一行,且不能省略。
encoding属性的缺省值为Uncode
XML 元素
1 | <element attribute_name = "attribute_value"> |
元素 element:是 XML 文档中最重要的组成部分。元素的命名规则为:
- 不能使用空格,不能使用冒号
- XML标签名称区分大小写
- XML必须有且只有一个根元素
XML 属性
1 | <element attribute_name1 = "attribute_value1" |
- 属性是元素的一部分,它必须出现在元素的开始标签
- 属性的值(
value)必须使用单引号或者双引号 - 一个元素中的元素不能同名
- 属性名必须以字母开头,不能使用空格、冒号等特殊符号
XML 注释
1 | <!-- 注释 --> |
XML 的注释,以 <!-- 开始,以 --> 结束。注释内容会被 XML 解析器忽略。
XML 预定义实体
我们在 XML 的语法中存在一些预先定义的字符,如 < > 等。所以我们在创建 XML 文件时当使用到这些字符时,需要如下的字符替换:
&&<<>>''""- 使用
<![CDATA[内容]]>将特殊的内容包含起来
2.4 XML Schema
我们之前介绍过,XML 的语法很严谨。与此同时,XML 的书写方式也十分灵活,在符合语法的基础上可以编写任意形式的文档来描述同一件事物。如下所示。
2
3
4
5
6
7
<resume>
<name>gdai</name>
<gender>male</gender>
<age>24</age>
<birthday>1998-01-01</birthday>
</resume>同样的内容我们可以使用另一种形式:
2
3
4
5
6
7
8
9
10
11
<resume>
<name>gdai</name>
<gender>male</gender>
<age>24</age>
<birthday>
<year>1998</year>
<month>1</month>
<day>1</day>
</birthday>
</resume>
通过以上例子我们可以看到,对于人来讲,上下两个示例都可以正确的理解。但是对于计算机来讲,对于 <birthday> 元素的理解大有不同。
所以为了避免这种情况,我们就需要一个相应的约束,来规定一个固定的格式,使得机器可以正确的识别、比较和处理。这也就是 DTD 和 Schema 所要完成的功能。
对于 DTD,由于 DTD 可以对 SGML 建立约束,且 XML 是从 SGML 发展而来,DTD 也可以对 XML 进行约束,但是其存在很多局限性。从而我们为 XML 设计了新的约束标准 Schema。下面我们给出一个 Schema 的例子:
1 | <!-- XML 序言--> |
其中:
content属性对元素中的数据进行说明,"eltOnly"值说明该元素的数据只能由元素构成
所以,我们可以看到经过这样的对元素进行定义,就可以定义一个嵌套结构的 XML 的树结构。
2.5 XML 命名空间
命名冲突
在 XML 中,元素名称是由开发者定义的,当两个不同的文档使用相同的元素名时,就会发生命名冲突。
这个 XML 文档携带着某个表格中的信息:
1 | <table> |
这个 XML 文档携带有关桌子的信息(一件家具):
1 | <table> |
假如这两个 XML 文档被一起使用,由于两个文档都包含带有不同内容和定义的 <table> 元素,就会发生命名冲突。XML 解析器无法确定如何处理这类冲突。
使用前缀来避免命名冲突
此文档带有某个表格中的信息:
1 | <h:table> |
此 XML 文档携带着有关一件家具的信息:
1 | <f:table> |
现在,命名冲突不存在了,这是由于两个文档都使用了不同的名称来命名它们的 <table> 元素 (<h:table> 和 <f:table>)。通过使用前缀,我们创建了两种不同类型的 <table>元素。
使用命名空间(Namespaces)
这个 XML 文档携带着某个表格中的信息:
1 | <h:table xmlns:h="http://www.w3.org/TR/html4/"> |
此 XML 文档携带着有关一件家具的信息:
1 | <f:table xmlns:f="http://www.w3school.com.cn/furniture"> |
与仅仅使用前缀不同,我们为 <table> 标签添加了一个 xmlns 属性,这样就为前缀赋予了一个与某个命名空间相关联的限定名称。
XML Namespace 属性
XML 命名空间属性被放置于元素的开始标签之中,并使用以下的语法:
1 | <prefix:example xmlns:prefix="namespaceURI"/> |
当命名空间被定义在元素的开始标签中时,所有带有相同前缀的子元素都会与同一个命名空间相关联。
注释:用于标示命名空间的地址不会被解析器用于查找信息。其惟一的作用是赋予命名空间一个惟一的名称。不过,很多公司常常会作为指针来使用命名空间指向实际存在的网页,这个网页包含关于命名空间的信息。
统一资源标识符(URI)
统一资源标识符是一串可以标识因特网资源的字符。最常用的 URI 是用来标示因特网域名地址的统一资源定位器 (URL)。另一个不那么常用的 URI 是统一资源命名 (URN)。在我们的例子中,我们仅使用 URL。
默认的命名空间
为元素定义默认的命名空间可以让我们省去在所有的子元素中使用前缀的工作。
请使用下面的语法:
1 | <example xmlns="namespaceURI"/> |
三、RDF(S)
RDF (Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF 形式上表示为“主 -谓-宾 ”(或“资源-属性-取值 ”)三元组,有时候也称为一条声明(Statement)。其中,取值可以视为一种特殊的、确定型的资源。
"三元组"是 RDF 的核心概念,指的是两个事物和它们之间的关系,其组成规范为:
我们同样可以使用带标签的图的方式来表示相同的三元组(一条带标签的有向边和两个带标签的节点)。
例如,三元组 对应的图为
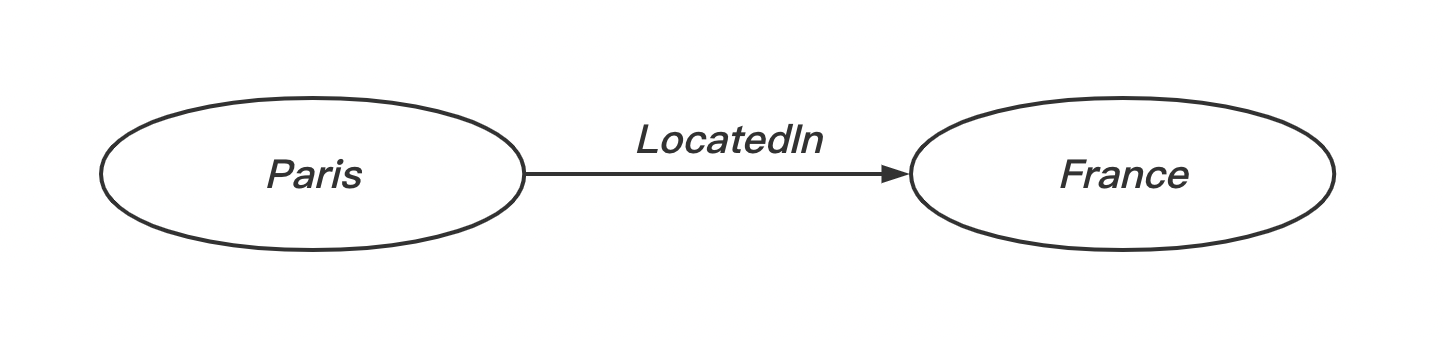
1 RDF 数据模型
1.1 资源
我们可以认为一个资源是一个对象,一个“事物”。每个资源都有一个 URI 或另一种唯一的标识符。其提供了一种机制来无歧义地表示我们相谈论的一个“事物”。
使用 URI 不必能访问到一个资源,但是使用可以解引用的 URL 作为 URI 是一个好方法。
当我们在定义词汇表时,我们经常在相同的 URI 中定义。即,在一个 RDF 模型中很多词汇都定义在了同一个 URL 下。类似于 XML 中的命名空间,这个 URL 可以定义为相应资源的命名空间 (NameSpace)。
-
在 XML-RDF 中,与 XML 中命名空间定义相同:
1
2
3
4
<rdf:RDF xmlns:ex="http://example.org/example#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
</rdf:RDF> -
在 Turtle 中,我们可以使用
@prefix xxx:<URL>.来缩写这个 URL。1
@prefix ex:<http://example.org/example.ttl>
资源在图 的概念中用节点(Node)来表示。在图中,大致有三种类型的节点:
-
URI 节点:所谓的 URI 节点,就是我们说到的,被无歧义表示的资源对象。
-
文字(Literal)节点:
- 由字面量与其数据类型组成,如
"1"^^<http://www.w3.org/2001/XMLSchema#integer> - 当数据类型缺省时,字面量为字符串型。
- 由字面量与其数据类型组成,如
-
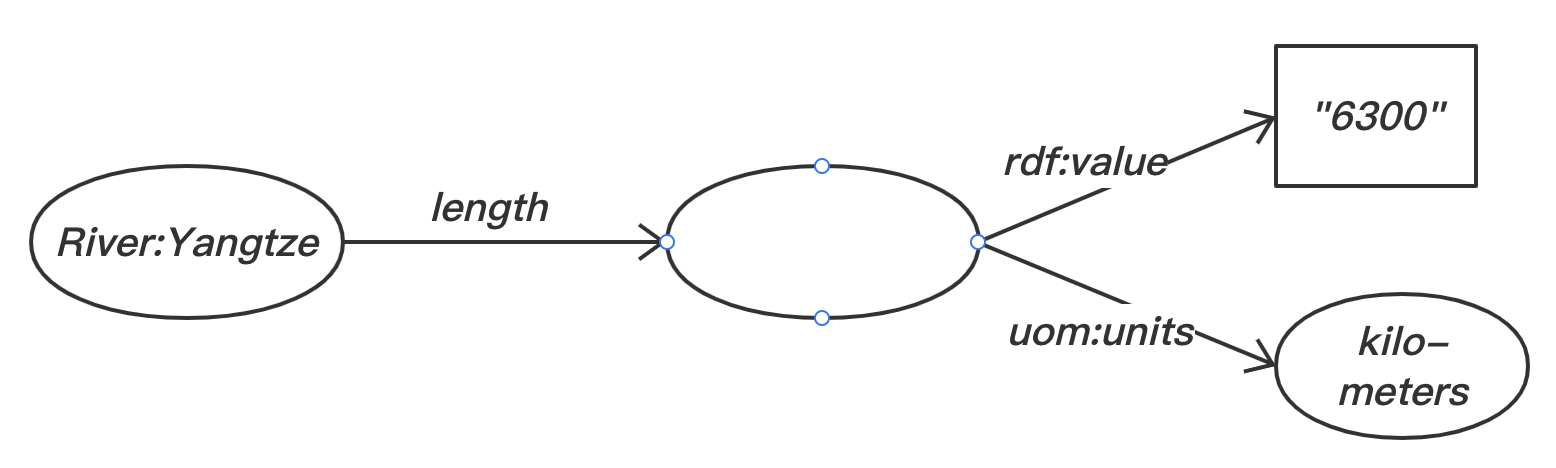
空节点:由于 RDF 的语法只能表示两者之间的关系,所以,当我们需要表示一对多的关系时,RDF 推荐的方案就是引入一个空节点(Blank Node),空节点的作用就是作为一个临时节点,或者说作为一个容器。
1.2 属性
属性是一种特殊的资源。它描述了资源之间的关系。例如,“Paris”和“France”是两个对象,“locatedIn“则可以描述两个对象资源之间的关系。和其他资源一样,属性也由 URI 唯一标识,同样可以使用 URL 作为 URI。
2 RDF 语法
2.1 RDF-XML 语法
如下所示是一个 XML 文档实例,它描述了有关“扬子江”的数据:
2
3
4
5
6
7
<River id="Yangtze"
xmlns="http://www.geodesy.org/river">
<length>6300 kilometers</length>
<startingLocation>Western China's Qinghai-Tibet Plateau</startingLocation>
<endingLocation>East China Sea</endingLocation>
</River>
2
3
Its startingLocation is Western China's Qinghai-Tibet Plateau.
Its endingLocation is East China Sea."
我们可以在上述 XML 文件语法的基础上,将其改写成 RDF 文件:
1 |
|
RDF/XML 是 RDF 在 XML 语言中的编码。 起初,RDF/XML 是 RDF 的唯一语法。但是,由 于 Turtle 通常更容易阅读,所以作为一种额外标准被采纳。
主语在一个 rdf:Description 元素中通过 rdf:about 定义(包含在尖括号内)。与主语关联的谓语和宾语也包含在 rdf: Description 元素中。命名空间可以通过 XML 命名空间结构( xmlns)被使用。所有的 RDF/XML必须被包含在一个 rdf:RDF 元素中。
词汇表
rdf:Description
使用该元素定义一个资源。可通过 rdf:about 属性使用一个完整的 URI(绝对 URI)来标识资源;也可以通过 rdf:ID 属性使用一个相对的 URI 来标识资源。
rdf:about: the resource needs to have a global identifier (absolute).rdf:ID: the resource has a local identifier (relative).
当定义的这个资源没有 URI 时,我们称这个资源为匿名资源(空白节点)。例
1 | <length> |
此时我们可以使用 rdf:parseType="Resource" 来代替
1 | <length rdf:parseType="Resource"> |
rdf:Resource
使用该元素定位到某一个特定资源。语法为 rdf:Resource="资源的URI"。
rdf:Property
使用该元素定义一个***属性***资源。其中,属性的本质也是一个资源。
rdf:Statement
使用该元素定义一个声明(三元组)。分别使用 rdf:subject、 rdf:perdicate 和 rdf:object 来定义主语、谓语和宾语。
Container
rdf:Alt 用来定义一个候选集合,rdf:Bag 来定义一个无序集合,rdf:Seq 用来定义一个序列。其中的每一个元素我们都用 rdf:li 来定义。
rdf:List
使用该元素定义一个列表结构资源。rdf:first 代表这个列表资源中的首个元素;rdf:rest 代表这个列表资源中的除了首个元素意外的其他元素;rdf:nil 代表一个空的列表元素的实例
rdf:type
使用该元素来声明一个类是另一个类的实例。
2.2 Turtle 语法
Turtle 是 RDF 图的文字表示,并且允许以紧凑的文本形式写下RDF图。它由一系列指令、三元组语句或空白行组成。Turtle 文本文件的后缀名是 .ttl。我们之前已经见到如何使用 Turtle 书写一个声明:
1 | <http://dbpedia.org/resource/Paris> |
其中,
- URL 包含在尖括号
<>之中; - 一个声明的主语、属性和宾语依次书写,最后以句号
.结尾; - 我们可以仅使用这种方法来编写整个 RDF 声明。
文字
之前我们讲过,我们也可以在 RDF 中引入文字,即原子值。在 Turtle 中,我们将值写在引号 "" 中,并在后面附上值的数据类型(整数、日期等)或者 @language 限定其语言。下面是一些常见的数据类型在 Turtle 中的形式:
string:"Paris"@enintegers:"1" ^^ <http://www.w3.org/2001/XMLSchema#integer>decimals:"1.11" ^^ <http://www.w3.org/2001/XMLSchema#deciaml>double:"4.2E9" ^^ <http://www.w3.org/2001/XMLSchema#double>boolean:"true" ^^ <http://www.w3.org/2001/XMLSchema#boolean>dates:"2022-11-23" ^^ <http://www.w3.org/2001/XMLSchema#date>time:"12:00:00" ^^ <http://www.w3.org/2001/XMLSchema#time>date with a time:"2022-11-23T12:00:00" ^^ <http://www.w3.org/2001/XMLSchema#dateTime>
假设我们要添加 “Paris has 20 arrondissement”,可以在之前的声明中加入
1 | <http://example.org/example.ttl#Paris> |
我们可以看到,上述例子相对而言并不容易使用。为了使其更加清晰,Turtle 提供了一些技巧来简化书写。
简写
当我们在定义词汇表时,我们经常在相同的 URI 中定义。我们可以在上一节的例子中看到,很多词汇都定义在了 http://example.org/example.ttl 这个 URL 下。类似于 XML 中的命名空间,这个 URL 定义相应资源的***命名空间 (NameSpace)***。在 Turtle 中,我们可以使用 @prefix xxx:<URL>. 来缩写这个 URL。例如
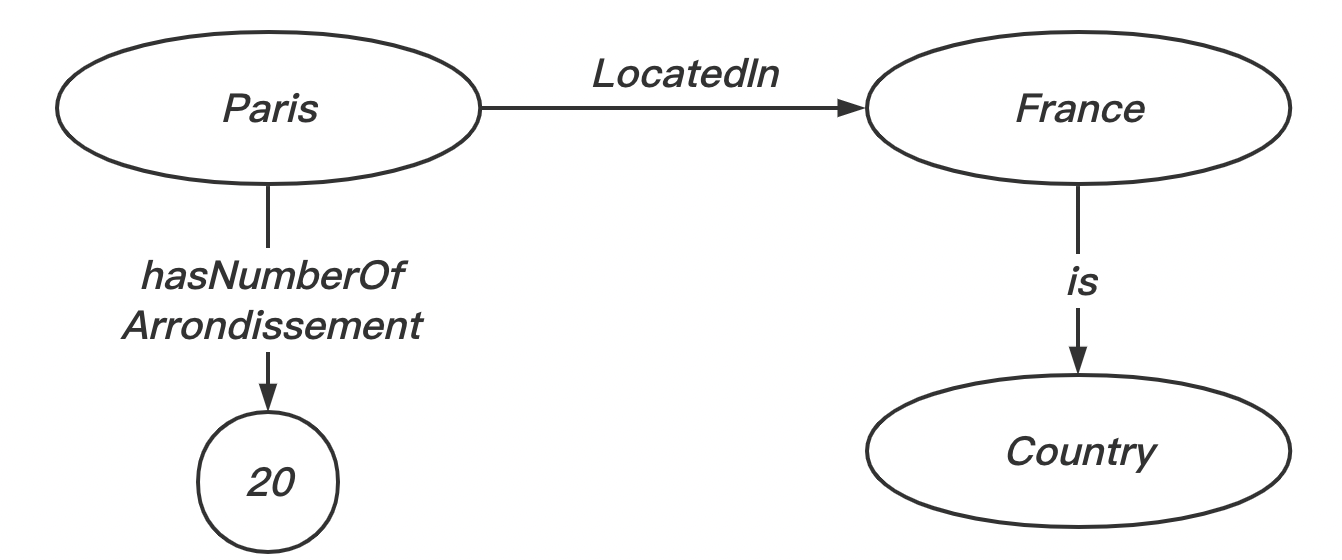
1 | @prefix ex:<http://example.org/example.ttl>. |
- 当我们重复使用某些主语时,可以在一段声明的结尾处使用分号
;来使得书写更精凑。
1 | @prefix ex:<http://example.org/example.ttl>. |
- 如果主语和谓语都被重复使用时,我们可以在在一段声明的结尾处使用逗号
,然后继续书写下一个相同主谓语声明中的宾语。例如我们添加 “Paris is located in Europe”:
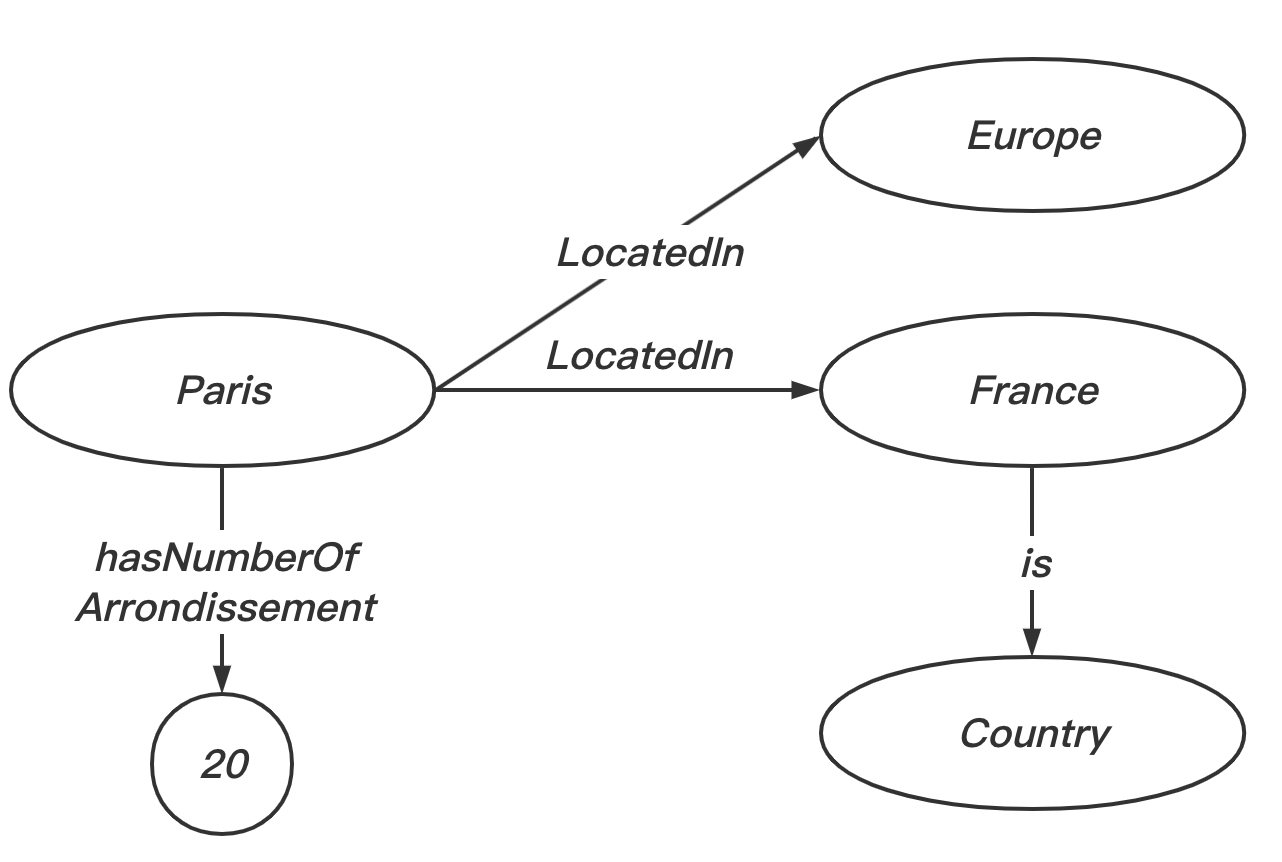
1 | @prefix ex:<http://example.org/example.ttl>. |
空节点
RDF 中的空节点由一个 “_:“ 后跟空白节点标签,后者是一系列名称字符。如 _:bob。空白节点标签有如下限制:
- 字符_和数字可以出现在空白节点标签中的任何位置。
- 字符 . 可能出现在除了第一个或最后一个字符外的任意位置。
- 除第一个字符外,都允许使用字符
-,U+00B7,U+0300到U+036F,U+203F到U+2040。
为文档中的每个唯一空节点标签分配新的 RDF 空白节点。重复使用相同的空白节点标签***【标识】***相同的 RDF 空白节点。

1 | @prefix foaf: <http://xmlns.com/foaf/0.1/> . |
在 Turtle 中嵌套未标记的空白节点
在 Turtle 中,当匹配产生 blankNodePropertyList 和终端 ANON 时,也分配新的 RDF 空白节点。这两者都可能出现在三元组的subject或object的位置(参见turtle语法)。该subject或object是新的RDF空白节点。此空白节点还用作通过匹配嵌入在blankNodePropertyList中的predicateObjectList生成而生成的三元组的subject。Predict 列表中描述了这些三元组的生成。还为下面描述的集合分配空白节点。
1 | PREFIX dbr: <http://dbpedia.org/resource/> |
3 RDFS
RDF Schema (RDFS) 是对 RDF 的一种扩展。RDFS 指明如何使用 RDF 来描述 RDF 词汇集,其中定义一个基本词汇集,和一种 RDF 扩展机制。
3.1 RDFS 类层次词汇表
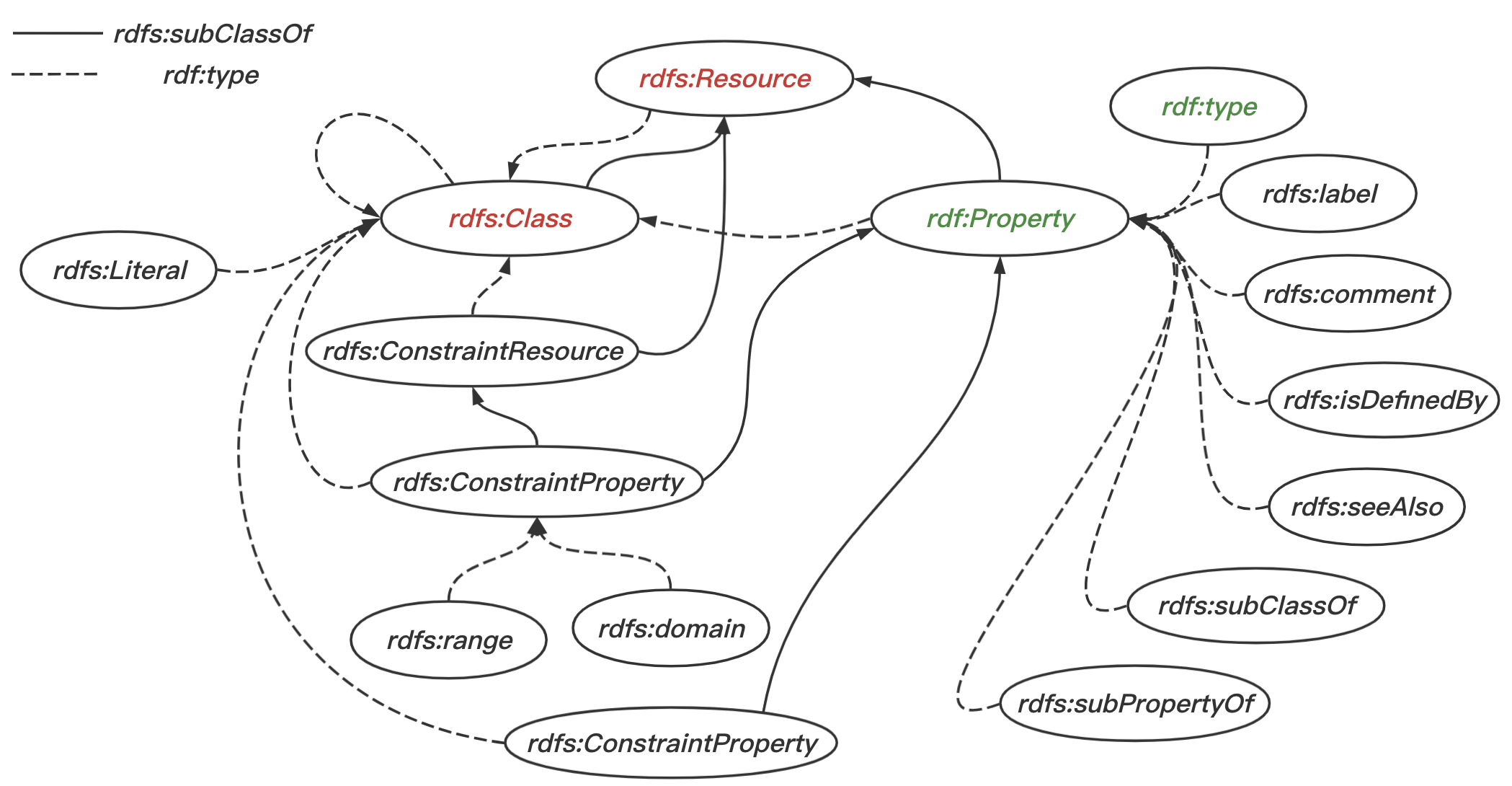
如上图,是 RDFS 的类层次结构。其中:
- 对于
rdf:Property来说,rdf:type、rdf:label等具体属性都是Property的实例。此外,rdf:Property还是rdfs:Resource的一个子类。 - 对于
rdfs:Class和rdfs:Resource来说,Class是Resource的一个实例,而同时,Class也是Resource的一个子类。
核心类
rdfs:Resource
通过RDF描述的事物被称为资源 (resource)。具体的资源被认为是 rdfs:Resource 类的一个实例 (instance)
rdfs:Resource类抽象表达了资源的集合
rdf:Property
使用 RDF 的命名空间。它是 RDF 资源的子集,用来表示属性,即集合中的所有元素被抽象地称为"属性"。
rdfs:Class
- 它对应类型或类别的概念,和面向对象程序设计(比如 Java)中的类相似。当一个模式定义一个新类时,表示该类的资源必须有一个
rdf:type属性,属性的值是rdfs:Class - RDF 类可以表达任何事物,例如网页、人、文档类型、数据库或抽象念
核心属性
每个使用了模式机制的 RDF 模型也(隐式地)包含了核心属性。它们是 rdf:Property 的实例,提供了一种表达类和它们的实例或超类之间关系的机制。
rdf:type
- 表明了一个资源是某个类的成员,因此它拥有类的成员所具有的所有特征
- 某个资源的
rdf:type属性的值是另一个资源,它必须是rdfs:Class子类 - 被称为
rdfs:Class的资源本身是类型为rdfs:Class的资源 - 个体类(例如“狗”)将有
rdf:type属性,它的值是rdfs:Class(或者rdfs:Class的某个子类) - 一个资源可以是多个类的实例(多类型)
rdfs:subClassOf
- 它指定了类之间的子集/超集关系
rdfs:subClassOf属性是传递的:如果类 A 是某个更广的类 B 的子类,而 B 又是 C 的子类,那么 A 也隐含地是 C 的子类- 只有
rdfs:Class的实例才能拥有rdfs:subClassOf属性,而它的属性值的类型总是rdfs:Class - 一个类可能是多个类的子类(多继承)
rdfs:subPropertyOf
- 是
rdf:Property的实例,指出一个属性是另外一个属性的具体化 - 一个属性可能是零个、一个或多个属性的具体化
- 如果某个属性 P2 是另一个更一般属性 P1 的子属性,而一个资源 A 的 P2 属性值为 B,那么意味着资源 A 的 P1 属性的值也是 B。
- 例如:
knows属性有一个子属性是isFriend。如果 A 与 BisFriend,那么 A 也knowsB。
- 例如:
rdfs:seeAlso
- 它指出了一个资源可能为主语资源提供额外的信息
- 这个属性可以使用
rdfs:subPropertyOf来更加具体化,以更精确地指出宾语资源与主语资源的具体关系- 例如,子属性
rdfs:isDefinedBy
- 例如,子属性
- 宾语和主语资源仅仅被约束为
rdfs:Resource类的实例
约束
rdfs:range
- 它是
rdf:Property的一个实例,用来指明一个属性的值域 - 值域约束只能被用于属性
- 可以没有值域,这样的话属性值的类型就没有约束
rdfs:domain
- 它是
rdf:Property的实例,用于指出一个属性的定义域 - 如果一个属性没有定义域属性,它可以被用于任何资源;如果它只有一个定义域属性,则可以被用于某个类的实例(这个类是定义域属性的值);
- 如果它拥有多个定义域属性,则被约束的属性可以被用于这些类的交集
文档标签
它们支持简单的文档和用户界面相关的标签,使用 xml:lang 标签可以从语法层次上支持多语言的模式文档
rdfs:comment:被用于提供一个人类可读的有关资源的描述rdfs:label:被用于提供一个人类可读的资源的名称
Container 成员关系
rdfs:ContainerMembershipProperty:这个类有属性成员 _1、_2、_3 … 被用于指出容器成员关系。
示例
1 | <rdf:RDF xml:lang="en" |
四、OWL
许多语言使用”面向对象“模型。这种模型便于理解、形式化程度高、适合机器处理:
- 对象/示例/个体:等价于一阶逻辑中的常量;
- 类型/类/概念:等价于二阶逻辑中的一元谓词;
- 关系/属性/角色:等价于一阶逻辑中的二元谓词。
RDFS 被认为是一个(简单的)本体语言。其具备类和属性,可以用来描述子类/父类、子属性/父属性的关系,属性的值域与定义域。但是其对于资源细节的描叙能力较弱:
-
没有局部的值域与定义域约束。“人”的
hasChild属性的值域是 “人”,而“大象”的hasChild属性的值域是“大象” -
没有存在/数量约束:“人”,的所有实例都有 “母亲”,或者“人”的双亲只能有两人
-
没有传递、相反或对称属性:
isPartOf是传递属性,hasPart是isPartOf的逆属性,或者touches是对称属性 -
很难提供推理支持:没有针对非标准语义的 “原生” 推理机,可能只能通过一阶逻辑公理来推理。
1 OWL 语言
OWL 是一门供处理 web 信息的、显式说明的 web 本体语言。其构建在 RDF 的顶端之上,用于处理 web 上的信息。OWL 被设计为供计算机进行解释,而不是被设计为供人类进行阅读的。
OWL 的 3 个子类:
OWL-Full是OWL语法和RDF的结合OWL-DL限制在描述逻辑 (DAML+OL)- 定义良好的语义
- 坚实的理论基础 (复杂度、可判定性)
- 知名的推理算法
- 高度优化的系统实现
OWL-Lite是OWL-DL的“容易实现的”子集
OWL 的语义分层
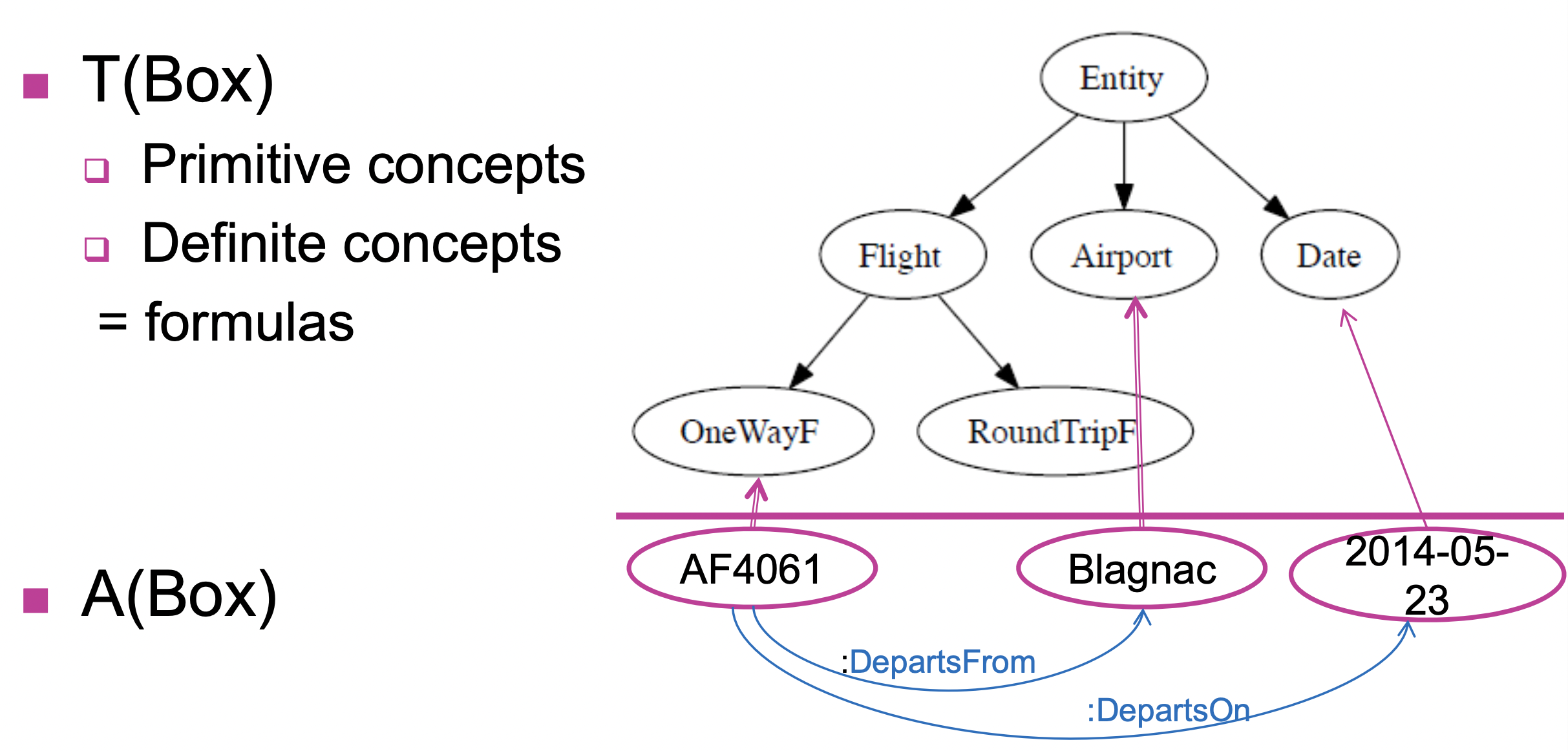
-
模式层(Terminology Box) 、实例层 (Assertion Box)
2 OWL 语法
OWL 语法在 RDFS 的基础上进一步进化。相同的,
-
owl:Ontology:OWL 文件的头 (Header),定义关于本体的元数据(描述信息)1
2
3
4<owl:Ontology rdf:about="">
<owl:versionInfo>v.1.0.0</owl:versionInfo>
<rdfs:comment>An example ontology.</rdfs:comment>
</owl:Ontology> -
owl:Class描述一个类1
<owl:Class rdf:ID="Human"/>
-
rdfs:subClassOf描述一个类是另一个类的子类1
2
3<owl:Class rdf:ID="Man">
<rdfs:subClassOf rdf:resource="#Human"/>
</owl:Class> -
owl:oneOf描述一个类由多个实例组成1
2
3
4
5<owl:Class rdf:ID="Continent"> <!-- 大洲 -->
<owl:oneOf rdf:parseType="Collection">
<owl:Thing rdf:about="#Afica"/> <owl:Thing rdf:about="#America"/> ...
</owl:oneOf>
</owl:Class> -
owl:disjointWith描述一个类不与另一个类有交集1
2
3<owl:Class rdf:ID="Male">
<owl:disjointWith rdf:resource="#Female"/>
</owl:Class> -
owl:unionOf描述多个类的并集1
2
3
4
5<owl:Class rdf:ID="MyHobbies">
<owl:unionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Cooking"/> <owl:Class rdf:about="#Hiking"/>
</owl:unionOf>
</owl:Class> -
owl:equivalentClass描述一个类是另一个类的等价类1
2
3<owl:Class rdf:ID="MyHobbies_equiv">
<owl:equivalentClass rdf:about="#MyHobbies"/>
</owl:Class> -
``
-
-
owl:Restriction为属性定义一个约束,owl:onProperty指定需要约束的属性1
2
3
4<owl:Restriction>
<owl:onProperty rdf:resource="#hasParent"/>
<owl:maxCardinality>2</owl:maxCardinality>
</owl:Restriction> -
owl:Property定义属性,其中分为两个部分,且两个部分没有交集:owl:objectProperty:值域为对象资源owl:datatypeProperty:值域为字面量信息
| Relation | DL 语法 | 示例 | Modal 语法 | 注释 |
|---|---|---|---|---|
owl:intersectionOf |
Human Male | 交集 | ||
owl:unionOf |
Doctor Lawyer | 并集 | ||
rdfs:subClassOf |
Human Animal | - | 子对象 | |
rdfs:subPropertyOf |
hasSon hasChild | - | 子属性 | |
owl:disjointWith |
不相交 | |||
owl:equivalentClass |
Man Human.male | - | 相同的类 | |
owl:equivalentProperty |
cost price | - | 相同的属性 | |
owl:inverseOf |
属性互为反向 | |||
owl:sameIndividualAs |
||||
owl:complementOf |
Male | 非 | ||
owl:oneOf |
{John} {Mary} | 点交集 | ||
owl:allValueFrom |
hasChild.Doctor | P 所有取值都来自 C | ||
owl:someValueFrom |
hasChild.Lawyer | P 个别取值来自 C | ||
owl:maxCardinality |
1hasChild | 最大基数 | ||
owl:minCardinality |
2hasChild | 最小基数 |
五、SPARQL
在本章中,我们将学习一个叫做 SPARQL 的查询语言,他能够让我们通过选择、抽取等方式从 RDF 中获取特定的部分。SPARQL 是专为 RDF(三元组存储库)设计的,与 SQL 等数据库查询语言相似。
每个三元组存储库都提供一个端点(endpoint),在此提交 SPARQL 查询。例如,DBPedia 提供了一个查询端点来查询 WikiPedia 的 RDF 表示,点此跳转。以下的所有查询示例也可以通过这个查询端点来测试。
SPARQL 查询的四种类型:
SELECT查询:返回变量绑定的结果;CONSTRUCT查询:返回WHERE中描述的 RDF 图;ASK查询:用于测试是否有满足WHERE的 RDF 子图(只关注是否有满足的查询结果);DESCRIBLE查询:用于得到关于某单个实体的描述信息(所有与实体相关的三元组)。
1 模式匹配
SPARQL 基于图模式(graph pattern)匹配,即 WHERE 的子句。在图模式中:
- 三元组模式,与 RDF 的三元组类似,不过主谓宾三个位置可以替换为变量。
- SPARQL 中有两种类型的图模式:Patterns on named graph 与 Group Graph Pattern。其中 Group Graph Pattern 的构成成分如下:
- 基本图模式(basic graph pattern)
- 过滤条件(filter condition)
- 可选图模式(optional graph pattern)
- 并列图模式(alternative graph pattern)
基本图模式
基本图模式是若干条三元组模式的集合,可以理解为所包含的若干条三元组的交集。
在此我们先简单提供一份描述 Baron Way 公寓及其位置的 RDF 数据作为示例:
1 | prefix swp:<http://semanticwebprimer.org/ontology/apartment.ttl#>. |
如果我们想在这段 RDF 数据中找出这幢建筑的位置:
-
首先,我们要先明确我们需要匹配的三元组:
1
swp:BaronWayBuilding dbpedia-owl:location dbpedia:Amsterdam, dbpedia:Netherland.
-
在 SPARQL 中,我们可以将三元组中任何一个元素替换为由一个问号
?起始的变量,在例子中我们使用?location:1
swp:BaronWayBuilding dbpedia-owl:location ?location .
-
三元组存储库会尝试去找到能够匹配这个语句的所有三元组集合。因此,返回的结果应该是
dbpedia:Amsterdam和dbpedia:Netherland作为谓语的三元组; -
完整的 SPARQL 的查询如下:
1
2
3
4
5
6
7prefix swp:<http://semanticwebprimer.org/ontology/apartment.ttl#>.
perfix dbpedia:<http://dbpedia.org/resurce/>.
perfix dbpedia-owl:<http://dbpedia.org/ontology/>.
SELECT ?location WHERE {
swp:BaronWayBuilding dbpedia-owl:location ?location .
}
SPARQL 的全部基础都是这个简单概念:尝试去找到匹配一个给定语句的三元组集合。我们也可以基于此,完成一些更加复杂的查询:
- 间接查询:查询中国首都的总人数
1 | PREFIX res:<http://dbpedia.org/resource/> |
- 匹配多个变量:查询中国首都的 URI 及其总人数
1 | PREFIX res:<http://dbpedia.org/resource/> |
ORDER BY语句:将查询后的结果按照一定的规则排序。ORDER BY ASC(?var) | DESC(?var)。LIMIT语句:在一些大型数据集上,查询返回的三元组可能会有很多条,我们可以用LIMIT语句来限制返回结果的数量。例如:查询中国各地区的人口数,并按照人口数量降序排序
1 | PREFIX res:<http://dbpedia.org/resource/> |
- 属性路径:SPARQL 中提供了一种精确表述属性链的方法。在简介查询的例子中,查询 BaronWayApartment 的位置,我们还可以改写成如下属性路径的形式。
1 | SELECT ?location WHERE { |
过滤条件 FILTER
过滤条件:为了满足在基本图模式中,可以对返回的结果作一些取值上的约束。
我们想在上述 RDF 数据中找出卧室数量小于 4 的公寓的名称及地址:
1 | SELECT ?apertment, ?location WHERE { |