我们可以思考如下场景:线程是一个系统资源,操作系统每分配一个线程,就会消耗一定的资源。如果在高并发的环境下, 我们为每个任务都创建一个线程的话,那么对资源的消耗时非常大的。为了减小在这中环境下的系统消耗,我们引入线程池概念来维护多个线程,将任务分配给线程池中的线程。
什么是线程池?
使用线程池的优势:
使用线程池可以统一的管理线程和控制线程并发数量;
可以与任务分离,提升线程重用度;
提升系统的响应速度
我们主要通过一下几个部分来介绍 Java 中的线程池:
自定义线程池 JDK 提供的线程池:ThreadPoolExecutor 设计模式 - 工作线程
我们在介绍 JDK 提供的线程池之前,先自定义一个线程池,以更好的了解线程池的工作方式。
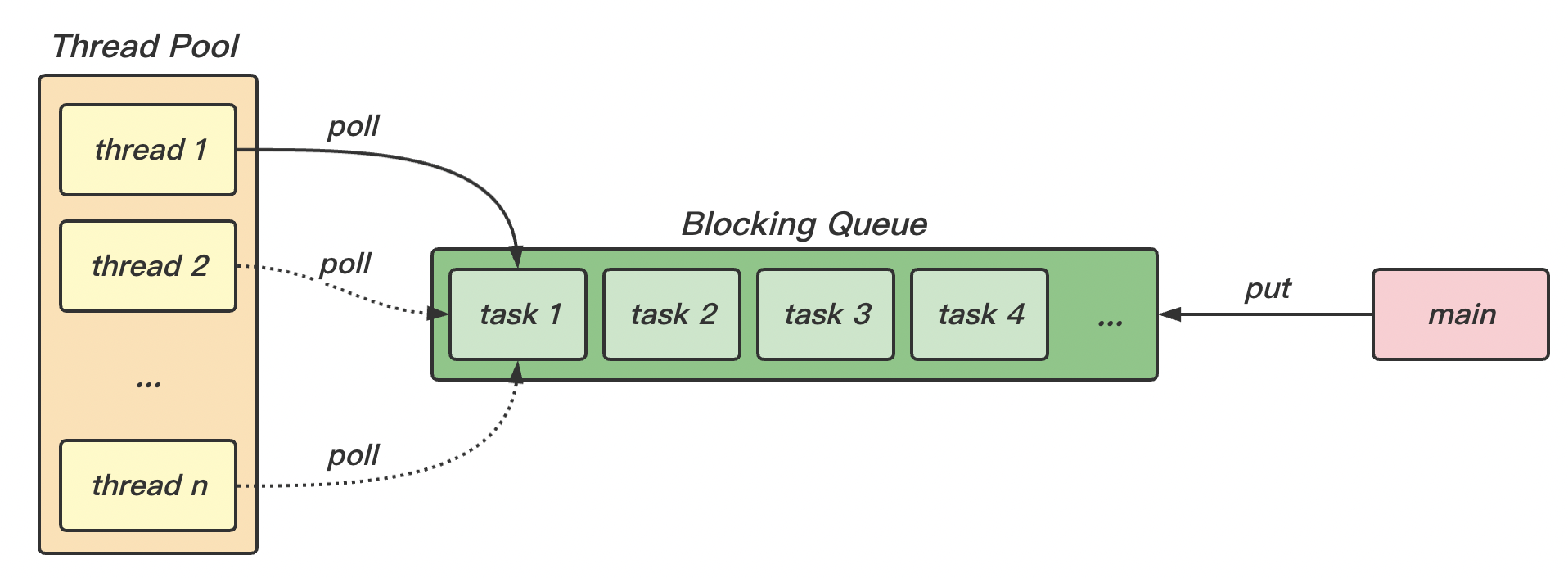
我们可以回忆一下生产者消费者问题 ,线程池其实就符合这个模型。线程池中的线程 thread 就是消费者task 就是商品main 就是生产者
下面我们分别实现上述部分。
BlockingQueue在这种“生产者消费者”模型下,生产与消费 task 的速率很可能是不一致的,生产的太多而来不及消费。此时我们就需要阻塞队列 BlockingQueue 来储存这些“产品”。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 public class MyBlockingQueue <T> { private Deque<T> queue = new ArrayDeque <>(); private int capacity; private ReentrantLock lock = new ReentrantLock (); private Condition fullWaitSet = lock.newCondition(); private Condition emptyWaitSet = lock.newCondition(); public MyBlockingQueue (int capacity) { this .capacity = capacity; } public T take () { lock.lock(); try { while (queue.isEmpty()) { try { emptyWaitSet.await(); } catch (InterruptedException e) { e.printStackTrace(); } } T t = queue.removeFirst(); System.out.println("从队列中取出一个任务" + t); System.out.println("队列中的元素有:\t" + queue.toString()); fullWaitSet.signal(); return t; } finally { lock.unlock(); } } public T poll (long timeout, TimeUnit unit) { lock.lock(); try { long nanos = unit.toNanos(timeout); while (queue.isEmpty()) { try { if (nanos <= 0 ) { return null ; } nanos = emptyWaitSet.awaitNanos(nanos); } catch (InterruptedException e) { e.printStackTrace(); } } T t = queue.removeFirst(); fullWaitSet.signal(); return t; } finally { lock.unlock(); } } public void put (T element) { lock.lock(); try { while (queue.size() == capacity) { try { System.out.println(element + " 等待加入任务队列..." ); fullWaitSet.await(); } catch (InterruptedException e) { e.printStackTrace(); } } queue.addLast(element); System.out.println("队列中的元素有:\t" + queue.toString()); emptyWaitSet.signal(); } finally { lock.unlock(); } } public boolean offer (T task, long timeout, TimeUnit timeUnit) { lock.lock(); try { long nanos = timeUnit.toNanos(timeout); while (queue.size() == capacity) { try { System.out.println(task + " 等待加入任务队列..." ); if (nanos <= 0 ) { System.out.println(task + " 等待时间超时,放弃!" ); return false ; } nanos = fullWaitSet.awaitNanos(nanos); } catch (InterruptedException e) { e.printStackTrace(); } } queue.addLast(task); System.out.println("队列中的元素有:\t" + queue.toString()); emptyWaitSet.signal(); return true ; } finally { lock.unlock(); } } public int size () { lock.lock(); try { return queue.size(); } finally { lock.unlock(); } } public void tryPut (MyThreadPool.RejectPolicy<T> rejectPolicy, T task) { lock.lock(); try { if (queue.size() == capacity) { rejectPolicy.reject(this , task); } else { queue.addLast(task); System.out.println("队列中的元素有:\t" + queue.toString()); emptyWaitSet.signal(); } } finally { lock.unlock(); } } }
ThreadPool1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class MyThreadPool { private MyBlockingQueue<Runnable> taskQueue; private HashSet<MyThread> threads = new HashSet <>(); private int coreNum; private long timeout; private TimeUnit timeUnit; public MyThreadPool (int coreNum, long timeout, TimeUnit timeUnit, int queueCapacity) { this .coreNum = coreNum; this .timeout = timeout; this .timeUnit = timeUnit; this .taskQueue = new MyBlockingQueue <>(queueCapacity); } public void excute (Runnable task) { if (threads.size() < coreNum) { Mythread t = new MyThread (task); threads.add(t); t.start(); } else { taskQueue.put(task); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class MyThread extends Thread { private Runnable task; public MyThread (Runnable task) { this .task = task; } @Override public void run () { while (task != null || (task = taskQueue.take()) != null ) { try { System.out.println(Thread.currentThread() + " 正在执行任务:" +task); task.run(); } catch (Exception e) { e.printStackTrace(); } finally { task = null ; } } synchronized (threads) { System.out.println("没有任务可以执行,从任务队列中移除 MyThread 对象 " + this ); threads.remove(this ); } } }
在使用无超时时间版本中,当任务数量较多时,产生任务的主线程就会阻塞。我们想根据不同的策略,让主线程进行不同的处理(继续死等或有时限的等待)。我们引入拒绝策略 RejectPolicy ,来增强线程池,使其可以使用不同的策略。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public class MyThreadPool { private MyBlockingQueue<Runnable> taskQueue; private HashSet<MyThread> threads = new HashSet <>(); private int coreNum; private long timeout; private TimeUnit timeUnit; private RejectPolicy<Runnable> rejectPolicy; public MyThreadPool (int coreNum, long timeout, TimeUnit timeUnit, int queueCapacity, RejectPolicy<Runnable> rejectPolicy) { this .coreNum = coreNum; this .timeout = timeout; this .timeUnit = timeUnit; this .taskQueue = new MyBlockingQueue <>(queueCapacity); this .rejectPolicy = rejectPolicy; } public void excute (Runnable task) { synchronized (threads) { if (threads.size() < coreNum) { MyThread t = new MyThread (task); System.out.println("新增 MyThread 对象" + t + "\t 来执行任务:" + task); threads.add(t); t.start(); } else { System.out.println("将任务:" +task + " 加入任务队列" ); taskQueue.tryPut(rejectPolicy, task); } } } }
1 2 3 4 5 @FunctionalInterface interface RejectPolicy <T> { void reject (MyBlockingQueue<T> taskQueue, T task) ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Test public void testMain () { MyThreadPool myThreadPool = new MyThreadPool (1 ,1000 , TimeUnit.MILLISECONDS, 1 , (queue, task) -> { }); for (int i = 0 ; i < 3 ; i++) { int j = i; myThreadPool.excute(() -> { try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(j); } ); } }
JDK 提供的线程池ThreadPoolExecutor这一小节,我们开始研究 JDK 给我提供的线程池 ThreadPoolExecutor。
ThreadPoolExecutor 使用 int 的高 3 位 来表示线程池状态 (最高位是符号位 ),低 29 位表示线程数量 。
1 2 3 4 5 6 private final AtomicInteger ctl = new AtomicInteger (ctlOf(RUNNING, 0 ));private static final int COUNT_BITS = Integer.SIZE - 3 ;private static final int CAPACITY = (1 << COUNT_BITS) - 1 ;
四种状态:
1 2 3 4 5 6 7 8 9 10 private static final int RUNNING = -1 << COUNT_BITS;private static final int SHUTDOWN = 0 << COUNT_BITS;private static final int STOP = 1 << COUNT_BITS;private static final int TIDYING = 2 << COUNT_BITS;private static final int TERMINATED = 3 << COUNT_BITS;
状态名
高 3 位
是否接收新任务
是否处理阻塞队列任务
说明
RUNNING111是
是
初始状态
SHUTDOWN000否
是
不会接收新任务,但会继续处理阻塞队列中剩余的任务
STOP001否
否
中断当前任务,并抛弃处理阻塞队列中的任务
TIDYING010-
-
过渡状态。任务执行完毕,即将进入终结状态
TERMINATED011-
-
终结状态
1 2 3 4 5 6 7 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
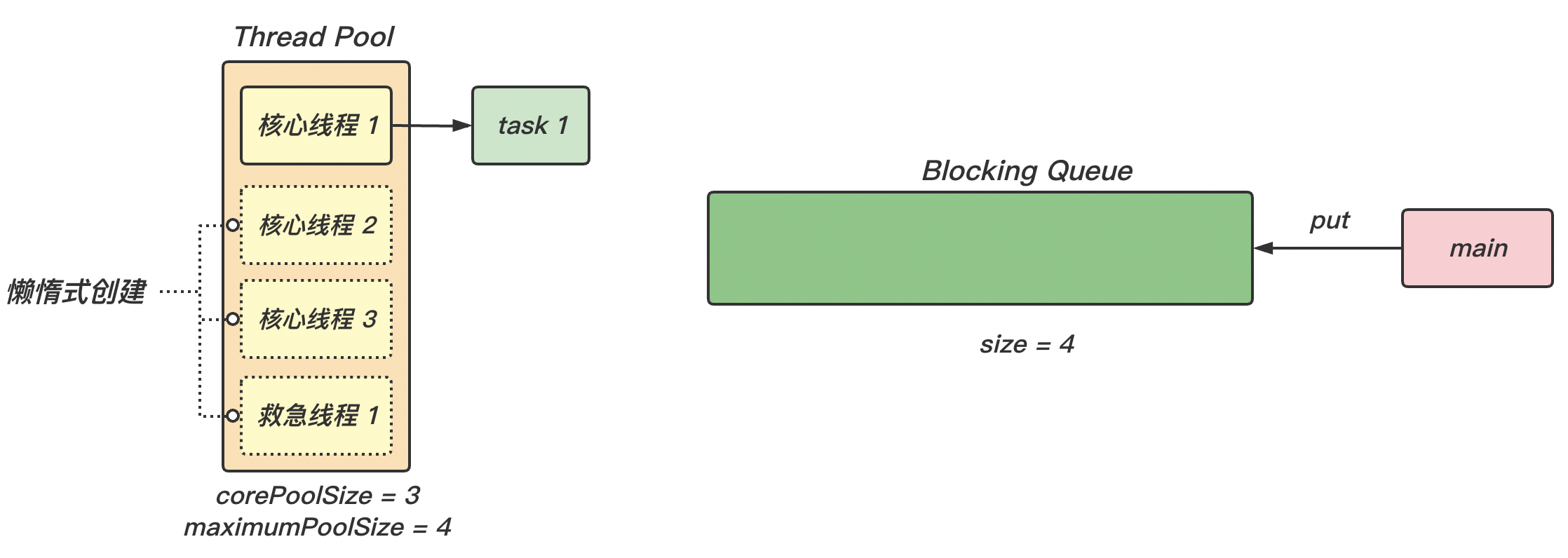
int corePoolSize:核心线程数(最多保留的线程数)int maximumPoolSize:最大线程数long keepAliveTime:针对救急线程的生存时间TimeUnit unit:生存时间的时间单位BlockingQueue<Runnable> workQueue:阻塞队列ThreadFactory threadFactory:线程工厂,可以在创建线程对象时起名,以区分不同的线程种类 (例如区分线程属于线程池或是其他类型)RejectedExecutionHandler handler:拒绝策略
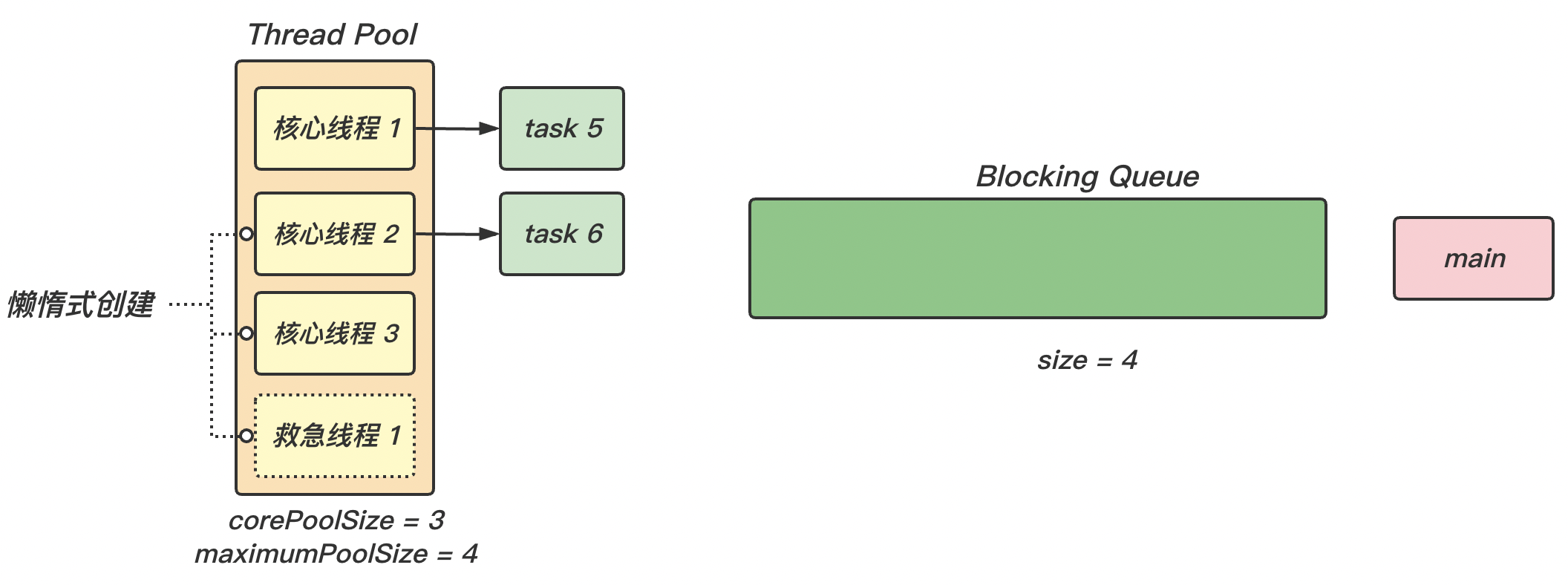
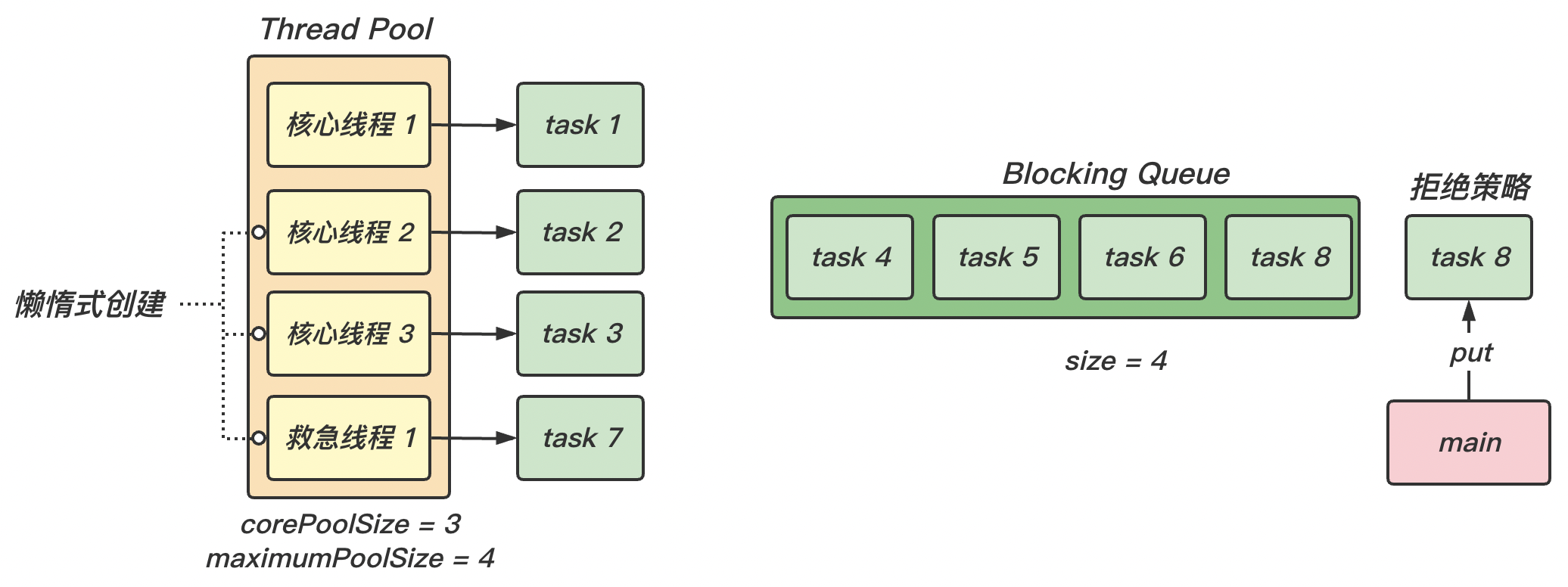
【图解】
(1)线程池中核心线程的创建是懒惰式 的,即只有当用到时才会创建。最大线程数 maximumPoolSize = 救急线程数 + 核心线程数 corePoolSize。
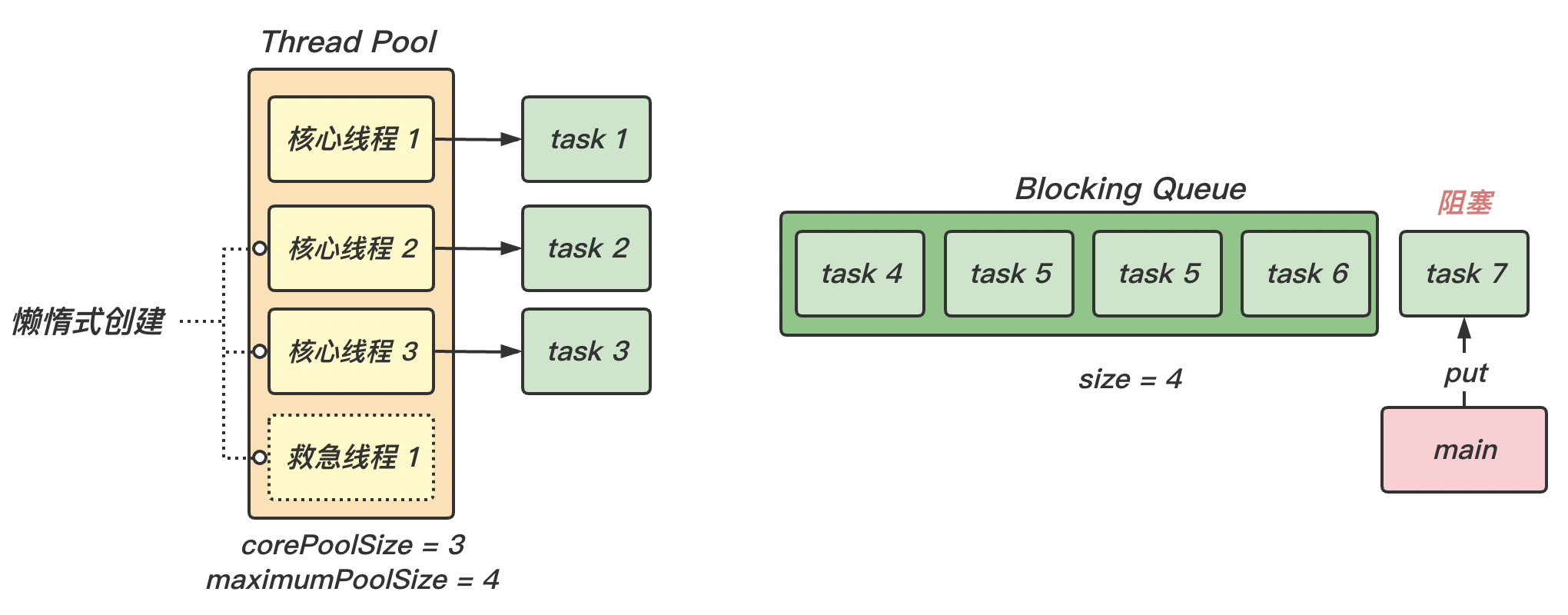
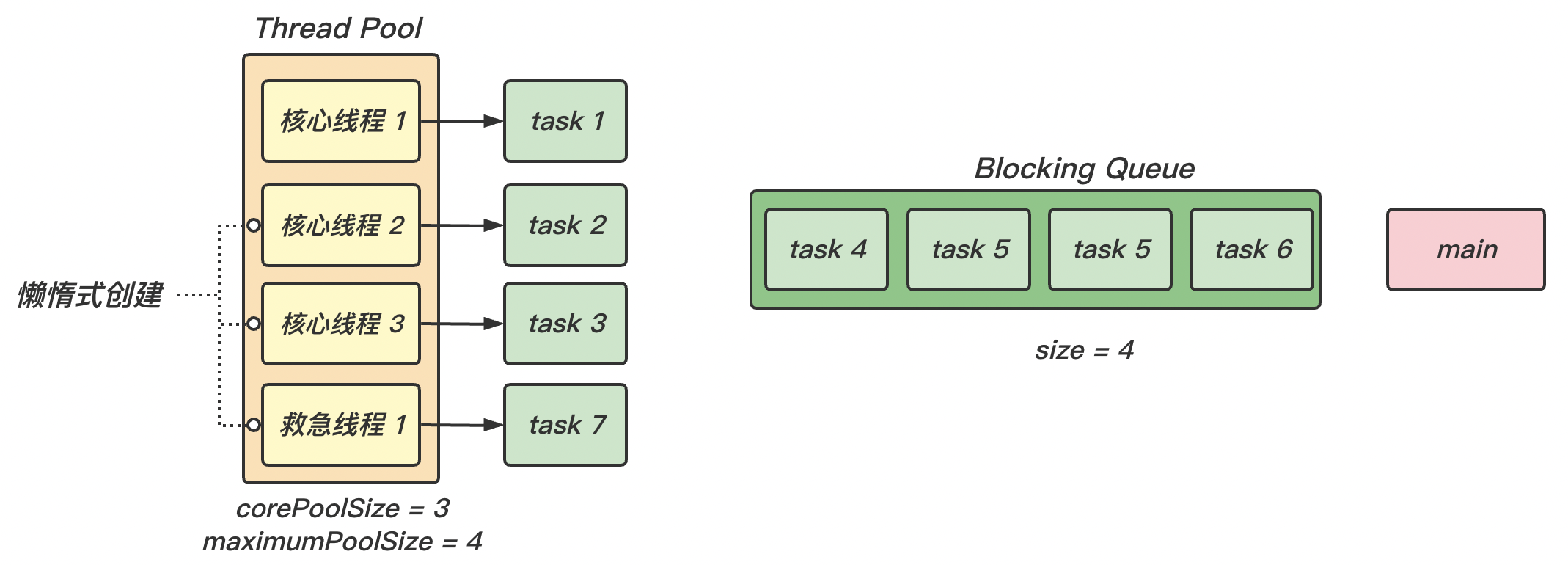
(2)随着任务的不断增加,核心线程都被分配了任务,且阻塞队列已满 ,那么新的任务就会被阻塞 。此时就是救急线程 工作的时候。
(3)救急线程存在生存时间 ,执行完任务后,一段时间内(keepAliveTime)没有使用,就会被销毁。
(4)当救急线程和核心线程都被分配了任务 ,且阻塞队列也已经满了 的情况下,才会执行拒绝策略 handler 。
(5)JDK 提供的拒绝策略:
AbortPolicy:让调用者抛出 RejectedExecutionException 异常,默认策略;
1 public static class AbortPolicy implements RejectedExecutionHandler
CallerRunsPolicy:让调用者执行任务;
1 public static class CallerRunsPolicy implements RejectedExecutionHandler
DiscardPolicy:放弃本次任务;
1 public static class DiscardPolicy implements RejectedExecutionHandler
DiscardOldestPolicy:放弃队列中最早的任务,本任务取而代之。
1 public static class DiscardOldestPolicy implements RejectedExecutionHandler
newFixedThreadPool固定大小线程池:
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) { return new ThreadPoolExecutor (nThreads, nThreads, 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>()); }
【特点】
核心线程数 = 最大线程数,即没有救急线程;
阻塞队列通过 LinkedBlockingQueue 实现,是无界的,可存放任意数量的线程对象。
newCachedThreadPool1 2 3 4 5 public static ExecutorService newCachedThreadPool () { return new ThreadPoolExecutor (0 , Integer.MAX_VALUE, 60L , TimeUnit.SECONDS, new SynchronousQueue <Runnable>()); }
【特点】
核心线程数为 0,最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60 秒,意味着
线程池中的线程全部都是救急线程 ;
救急线程可以无限创建。
阻塞队列通过 SynchronousQueue 实现,没有容量。意为只要有任务就用救急线程执行。
newSingleThreadExecutor单线程线程池
1 2 3 4 5 6 public static ExecutorService newSingleThreadExecutor () { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor (1 , 1 , 0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>())); }
【特点】
只有一个核心线程,多个任务排队执行。任务执行完毕后,该核心线程也不会被释放。
与 new Thread 创建一个线程串行执行的区别:如果线程在执行任务时由于意外结束,线程池会重新创建一个线程继续执行队列里的任务。
FinalizableDelegatedExecutorService 应用装饰器模式 ,只对外暴露了 ExecutorService 接口,不能调用 ThreadPoolExecutor 的特有方法(修改线程数等)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void execute (Runnable command) ;<T> Future<T> submit (Callable<T> task) ; <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException; <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; <T> T invokeAny (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
execute()对于第一种最普通的执行任务的方法 execute(task),我们可以看到它时没有返回值的;
1 2 public void execute (Runnable command) ;
例:
1 2 3 4 5 6 7 8 9 10 11 @Test public void testSubmit () throws ExecutionException, InterruptedException { ExecutorService threadPool = Executors.newFixedThreadPool(2 ); Future<String> future = threadPool.submit( () -> {Thread.sleep(1000 ); return "ok" ;} ); System.out.println(future.get()); }
submit()对于 submit() 方法是有返回值的,可以只用 Future 对象来接收返回值
1 2 <T> Future<T> submit (Callable<T> task) ;
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test public void testSubmit () { ExecutorService threadPool = Executors.newFixedThreadPool(2 ); Future<String> future = threadPool.submit(() -> { try { Thread.sleep(1000 ); return "ok" ; } catch (InterruptedException e) { e.printStackTrace(); } }); System.out.println(future.get()); }
输出:
invokeAll()invokeAll() 方法的输入 是一个任务的集合 ,返回结果的集合 :
1 2 3 4 5 6 7 8 <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Test public void testInvokeAll () throws InterruptedException, ExecutionException { ExecutorService threadPool = Executors.newFixedThreadPool(2 ); List<Future<String>> future = threadPool.invokeAll(Arrays.asList( () -> { Thread.sleep(1000 ); return "thread_1" ;}, () -> { Thread.sleep(500 ); return "thread_2" ;}, () -> { Thread.sleep(3000 ); return "thread_3" ;} )); for (Future<String> f:future) { System.out.println(f.get()); } }
输出:
1 2 3 thread_1 thread_2 thread_3
invokeAny()invokeAny() 方法的输入 是一个任务的集合 ,返回第一个执行结束的任务的结果,其他任务取消 :
1 2 3 4 5 6 7 8 <T> T invokeAny (Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; <T> List<Future<T>> invokeAll (Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
例如
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void testInvokeAny () throws ExecutionException, InterruptedException { ExecutorService threadPool = Executors.newFixedThreadPool(2 ); String result = threadPool.invokeAny(Arrays.asList( () -> { Thread.sleep(1000 ); return "thread_1" ;}, () -> { Thread.sleep(500 ); return "thread_2" ;}, () -> { Thread.sleep(3000 ); return "thread_3" ;} )); System.out.println(result); }
输出:
shutdown()停止线程池,线程池状态变为 SHUTDOWN
不会接受新任务
会把已提交的任务和队列中的任务执行完毕
调用时不会阻塞调用线程(主线程)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public void shutdown () { final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(SHUTDOWN); interruptIdleWorkers(); onShutdown(); } finally { mainLock.unlock(); } tryTerminate(); }
shutdownNow()直接关闭线程池,不会等待任务执行完成。线程池状态变为 STOP
不会接受新任务
将队列中的任务丢弃
使用 interrupt 方法打断正在执行的任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public List<Runnable> shutdownNow () { List<Runnable> tasks; final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { checkShutdownAccess(); advanceRunState(STOP); interruptWorkers(); tasks = drainQueue(); } finally { mainLock.unlock(); } tryTerminate(); return tasks; }
tryTerminate()设置为 TERMINATED 状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 final void tryTerminate () { for (;;) { int c = ctl.get(); if (isRunning(c) || runStateAtLeast(c, TIDYING) || (runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty())) return ; if (workerCountOf(c) != 0 ) { interruptIdleWorkers(ONLY_ONE); return ; } final ReentrantLock mainLock = this .mainLock; mainLock.lock(); try { if (ctl.compareAndSet(c, ctlOf(TIDYING, 0 ))) { try { terminated(); } finally { ctl.set(ctlOf(TERMINATED, 0 )); termination.signalAll(); } return ; } } finally { mainLock.unlock(); } } }
让有限的工作线程 (Worker Thread)来轮流异步处理无限多的任务 。也可以将其归类为分工模式,它的典型实现就是线程池 ,也体现了经典设计模式中的享元模式 。
例如,
一个餐馆的服务员们(线程),轮流处理每位客人的点餐(任务),如果为每位客人都配一名专属的服务员,那么成本就太高了 (对比另一种多线程设计模式:Thread-Per- Message)
注意,不同任务类型应该使用不同的线程池 ,这样能够避免饥饿,并能提升效率。
例如,
如果服务员们(线程)既要招呼客人(任务类型A),又要到后厨做菜(任务类型B)。 显然效率不高,分成服务员(线程池A) 与厨师(线程池B) 更为合理。
【注意 ⚠️】要与线程的“死锁与饥饿” 的概念区分开。固定大小线程池 会有饥饿现象。
例如,
两位服务员(线程)是同一个线程池中的两个线程。他们要做的事情是:为客人点餐 和到后厨做菜 ,这是两个阶段的工作:
客人点餐:必须先点完餐,等菜做好,上菜,在此期间处理点餐的工人必须等待 ;
后厨做菜:做菜。
比如服务员 A 处理了点餐任务,接下来它要等着服务员 B 把菜做好,然后上菜。但现在同时来了两个客人 ,这个时候服务员 A 和服务员 B 都去处理点餐了,这时没人做饭了,这时发生了饥饿现象。
不同任务类型应该使用不同的线程池 ,这样能够避免饥饿,并能提升效率。
【线程池过小 】会导致程序不能充分地利用系统资源、容易导致饥饿
【线程池过大 】会导致更多的线程上下文切换,占用更多内存,容易 OOM
通常采用
C P U 核 心 数 + 1 CPU 核心数 + 1
C P U 核 心 数 + 1
能够实现最优的 CPU 利用率,+ 1 +1 + 1
CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用CPU资源,但当你执行 I/O 操作时、远程 RPC 调用(HTTP socket)时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下:
线 程 数 = 核 心 数 × 期 望 C P U 利 用 率 × 总 时 间 ( = C P U 计 算 时 间 + 等 待 时 间 ) ÷ C P U 计 算 时 间 线程数 = 核心数 \times 期望 CPU 利用率 \times 总时间_{(=CPU计算时间+等待时间)} \div CPU 计算时间
线 程 数 = 核 心 数 × 期 望 C P U 利 用 率 × 总 时 间 ( = C P U 计 算 时 间 + 等 待 时 间 ) ÷ C P U 计 算 时 间
例如 4 核 CPU 计算时间是 50%,其它等待时间是 50%,期望 CPU 被 100% 利用,套用公式
1 4 * 100 % * 100 % / 50 % = 8
例如 4 核 CPU 计算时间是 10%,其它等待时间是 90%,期望 CPU 被 100% 利用,套用公式
1 4 * 100 % * 100 % / 10 % = 40