写在前面:
我们在学习 Java 并发编程 时已经知道, synchronized 的本质是对 ObjectMonitor 对象的操作。在本章中我们会讲解一种相对于 Monitor(悲观锁)来实现线程安全的模式(乐观锁)。但碍于学识浅薄,文章中难免会出现错误,恳请各位读者加以指正。
我们主要通过以下几个方面来系统的介绍“乐观锁”的实现原理:
CAS 与 violate- 原子整数
AtomicInteger
- 原子引用
AtomicReference
- 原子数组
AtomicArray
- 原子累加器
Unsafe 类
相关资料:
- 关于
ObjectMonitor 的底层源码分析
- Java 中的锁:
ReentrantLock
- Java 内存模型 - JMM
0 引出问题
我们思考这样一个场景:
对于一个临界区数据 count,分别有两个线程对 count 进行增减操作。
如果我们使用 synchronized 关键字来对 count 进行保护,简易代码如下:
1
2
3
4
5
| synchronized class Count {
int num;
public void increse(int i) { this.num += i;}
public void decrese(int i) { this.num -= i;}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| class Operate {
public static void main(String[] args) {
Count count = new Count(0);
new Thread (() -> {
count.increase(1);
},"t1").start();
new Thread (() -> {
count.decrease(1);
},"t2").start();
}
}
|
但是我们能否不使用 synchronized 就可保护 count 呢?当然可以:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class Count {
private AtomicInteger num;
public void increase(int i) {
while(true) {
int prev = this.num;
int succ = prev + i;
if (num.compareAndSet(prev,succ)) {
break;
}
}
}
public void decrease(int i) {...}
}
|
我们可以看到,通过使用 AtomicInteger 可以通过调用其 compareAndSet(以下简写为 CAS)方法同样可以保证线程安全。那么为什么呢?
1 CAS 与 volatile
CAS 分析
前面我们看到, AtomicInteger 的 CAS 方法同样可以保证线程安全。下面我们就来分析 incease() 代码块中的执行流程:
sequenceDiagram
participant t1 as 线程1(CPU 0)
participant obj as Count 对象
participant t2 as 线程2(CPU 1)
Note over obj :num = 10
t1 ->> obj :获取 num = 10
Note over t1 :prev = 10
t2 -->> obj :⚠️ CAS更改 num = 5 成功 ✅
Note over obj :num = 5
t1 ->> t1 :increase(1)
Note over t1 :succ = 11
t1 ->> obj :compareAndSet(10,11) ❌
t1 ->> obj :获取 num = 5
Note over t1 :prev = 5
t1 ->> t1 :increase(1)
Note over t1 :succ = 6
t1 ->> obj :compareAndSet(5,6) ✅
Note over obj :num = 6
我们在上述的流程图中可以看出:
CAS 是原子操作,是一种系统原语:
- 原语由若干条指令组成的,用于完成一定功能的一个过程;
- 原语的执行必须是连续的,在执行过程中不允许被中断。
- 在执行
CAS 操作时,会先比较 prev 的值与原来的值是否一致,
- 若一致,则更新原来的值为
succ 的值;
- 若不一致,不进行操作。
CAS 的核心思想是当修改时的值与当初获得时的值【一致】时,我们才会修改它;否则就不断重试,直至成功。
注意 ⚠️
- 其实
CAS 的底层是 lock cmpxchg 指令(x86 架构下),在单核 CPU 和多核 CPU 下都能够保证 CAS 的原子性。
- 在多核 CPU 状态下,某个 CPU 执行到
lock 指令后,CPU 会锁住总线,当这个 CPU 核心将该指令执行完毕后再开启总线。整个过程不会被线程的调度机制打断,保证了多个线程对内存操作的原子性。
violatile 的可见性
通过上述分析,我们可以想到:
原始变量的值在 CAS 操作中至关重要,要保证它的值始终都是“最新”的,即直接操作原始变量的主存地址的值。
所以我们可以使用之前学过的 violatile 关键字来确保变量的可见性(详见 Java 内存模型 - JMM)
violatile 可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作内存中查找变量的值,必须要主存中获取值。线程操作使用 violatile 关键字修饰的变量都是直接操作主存。即一个线程对 violatile 变量的操作,对另一个线程是可见的。
CAS 必须借助 volatile 才能读取到共享变量的最新值,我们可通过分析 AtomicInteger 的源码可以看到:
1
2
3
4
5
6
7
8
9
10
11
12
| public class AtomicInteger extends Number implements java.io.Serializable {
...
private volatile int value;
public AtomicInteger { value = 0; }
public AtomicInteger(int initialValue) {
value = initialValue;
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
}
|
为什么乐观锁的效率高呢?
这里的运行效率是在多核心 CPU 的条件下讨论的,因为单核心 CPU 下没有意义,均为串行。
- 乐观锁的情况下,即使
CAS 操作失败,线程仍然会不停的重试,而不是被阻塞,从而不会发生上下文转换;RUNNABLE
- 悲观锁的情况下,同一时刻只有一个线程获得
ObjectMonitor 锁对象,其他获取锁对象失败的线程则会被阻塞在 EntryList 等待队列中 Owner 线程释放锁。RUNNABLE --> BLOCKED
个人理解:
在多 CPU 系统下,
- 乐观锁是一种宏观上的真实的并行
- 悲观锁是一种虚假的并行(某种程度上可看作是串行)
我们可以从流程图直观地看出:
【乐观锁】
sequenceDiagram
participant t1 as 线程1(CPU 0)
participant obj as 临界区对象
participant t2 as 线程2(CPU 1)
t1 ->> obj : CAS ✅
t2 -->> obj : ❌ CAS
t2 -->> t2 : 重试
t2 ->> obj : ✅ CAS
【悲观锁】
sequenceDiagram
participant t1 as 线程1(CPU 0)
participant obj as ObjectMonitor
participant t2 as 线程2(CPU 1)
t1 ->> +obj : 【获得】锁对象成功 ✅
note over t1 : 执行临界区代码
t2 -->> obj : ❌ 【获得】锁对象失败
note over t2 : 阻塞
obj ->> -t1 : 【释放】锁对象
obj -->> t2 : 【唤醒】等待的线程
t2 ->> obj : ✅【获得】锁对象成功
CAS 的特点
结合 CAS 和 volatile 可以实现无锁并发与无阻塞并发,适用于线程数少、多核 CPU 的场景。
CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,线程会不断尝试重新修改。synchronized 是基于悲观锁的思想:最悲观的估计,提防其它线程来修改共享变量,上了锁后其他线程都不能修改。只有释放锁,其他线程才有机会。- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响(CPU 占用率高)。
下面我们将介绍一些使用了 CAS 方法的工具类。
2 原子整数 AtomicInteger
java.util.concurrent 包提供了 AtomicInteger、AtomicBoolean 和 AtomicLong 等原子性的基本数据类型。其底层都是依靠 CAS 实现。这些原子数据类功能类似,这里我们以 AtomicInteger 为例,进行研究。
AtomicInteger 方法摘要
| 函数名 |
返回值类型 |
解释 |
get() |
int |
获取当前值。 |
set(int newValue) |
void |
设置为给定值 newValue。 |
lazySet(int newValue) |
void |
最后设置为给定值 newValue。 |
getAndSet(int newValue) |
int |
以原子方式设置为给定值,并返回旧值。 |
intValue() |
int |
以 int 形式返回指定的数值。 |
doubleValue() |
double |
以 double 形式返回指定的数值。 |
floatValue() |
float |
以 float 形式返回指定的数值。 |
longValue() |
long |
以 long 形式返回指定的数值。 |
toString() |
String |
返回当前值的字符串表示形式。 |
compareAndSet(int expect, int update) |
boolean |
如果当前值 == 预期值,则以原子方式将该值设置为给定的更新值。 |
weakCompareAndSet(int expect, int update) |
boolean |
如果当前值 == 预期值,则以原子方式将该设置为给定的更新值。 |
incrementAndGet() |
int |
以原子方式将当前值加 1。等同于 ++i,先自增再赋值 |
getAndIncrement() |
int |
以原子方式将当前值加 1。等同于 i++,先赋值再自增 |
decrementAndGet() |
int |
以原子方式将当前值减 1。等同于 --i,先自减再赋值 |
getAndDecrement() |
int |
以原子方式将当前值减 1。等同于 i--,先赋值再自减 |
addAndGet(int delta) |
int |
以原子方式将给定值与当前值相加。先加 delta 再赋值 |
getAndAdd(int delta) |
int |
以原子方式将给定值与当前值相加。先赋值再加 delta |
updateAndGet(IntUnaryOperator updateFunction) |
int |
以原子方式将给定值按照 updateFunction 函数进行运算。先运算再赋值。(用法详见下文) |
getAndUpdate(IntUnaryOperator updateFunction) |
int |
以原子方式将给定值按照 updateFunction 函数进行运算。先赋值再运算。 |
我们在上述方法中发现存在这样一个方法:getAndUpdate(IntUnaryOperator updateFunction),那么这个方法表示什么含义呢?我们观察一下它的源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public final int getAndUpdate(IntUnaryOperator updateFunction) {
int prev, next;
do {
prev = get();
next = updateFunction.applyAsInt(prev);
} while (!compareAndSet(prev, next));
return prev;
}
|
1
2
3
4
5
6
7
8
9
10
11
| @FunctionalInterface
public interface IntUnaryOperator {
...
default IntUnaryOperator compose(IntUnaryOperator before) {
Objects.requireNonNull(before);
return (int v) -> applyAsInt(before.applyAsInt(v));
}
}
|
理解了上述内容后,我们测试一下该方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class AtomicIntegerTest {
@Test
public void testGetAndUpdate() {
AtomicInteger i = new AtomicInteger(10);
i.getAndUpdate(value -> value*10);
System.out.println(i.get());
}
@Test
public void testUpdateAndGet() {
AtomicInteger i = new AtomicInteger(10);
i.updateAndGet(value -> value*10);
System.out.println(i.get());
}
}
|
3 原子引用 AtomicReference
我们需要保护的数据对象并不都是基本数据类型,所以下面我们介绍原子引用,来保护其他的数据类型。
注意 ⚠️
原子引用 AtomicReference 保护的是多个线程对一个对象整体的引用进行修改时的线程安全性。即引用对象整体的地址,而不是引用对象的值。(这一点可从下述的例子中看出)
原子引用分为:AtomicReference、AtomicMarkableReference 和 AtomicStampedReference
AtomicReference
我们先以 AtomicReference 为例进行讲解:
基本用法:AtomicReference<typeOfObject> nameOfObject 使用泛型对保护对象进行包装
1
2
3
4
| interface DecimalAccount {
BigDecimal getBalance();
void withdraw(BigDecimal amount);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class DecimalAccountCASImpl implements DecimalAccount {
private AtomicReference<BigDecimal> balance;
public DecimalAccountCASImpl(BigDecimal balance){
this.balance = new AtomicReference<>(balance);
}
@override
BigDecimal getBalance(){
return balance.get();
}
@override
void withdraw(BigDecimal amount){
do {
BigDecimal prev = balance.get();
BigDecimal next = prev.substract(amount);
} while (!balance.compareAndSet(prev, next));
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class DecimalAccountTest {
@Test
public void testWithdraw() {
DecimalAccount account = new DecimalAccountCASImpl(new BigDecimal("10000"));
new Thread(() -> {
account.withdraw(new BigDecimal("5000"));
},"t1").start();
new Thread(() -> {
account.withdraw(new BigDecimal("1000"));
},"t2").start();
new Thread(() -> {
account.withdraw(new BigDecimal("1000"));
},"t2").start();
System.out.println(account.getBalance());
}
}
|
ABA 问题
思考
compareAndSet() 方法的核心在于当修改时的值与当初获得时的值【一致】时,我们才会修改它。但是并不能判断这个值是否被修改过。如下图所示
sequenceDiagram
participant t1 as 线程1(CPU 0)
participant obj as AtomicReference
participant t2 as 线程2(CPU 1)
note over obj : "a"
obj ->> t1 : get()
note over t1 : Sting prev = "a"
t2 -->> obj : ⚠️ CAS("a", "b") ✅
note over obj : "b"
t2 -->> obj : ⚠️ CAS("b", "a") ✅
note over obj : "a"
t1 ->> obj : CAS(prev, "c") ✅
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class AtomicReference_of_String {
static AtomicReference<String> ref_String = new AtomicReference<>("a");
public static void main(String[] args) throws InterruptedException {
String prevRef = ref_String.get();
System.out.println("main : prevRef = " + prevRef);
otherThreadsWorking();
Thread.sleep(1000);
System.out.println("main : change 'a' -> 'c': " +
ref_String.compareAndSet(prevRef, "c"));
}
static void otherThreadsWorking() throws InterruptedException {
new Thread(() -> {
String prevRef = ref_String.get();
System.out.println("t1 : prevRef = " + prevRef);
System.out.println("t1 : change 'a' -> 'b': " +
ref_String.compareAndSet(prevRef, "b"));
},"t1").start();
Thread.sleep(500);
new Thread(() -> {
String prevRef = ref_String.get();
System.out.println("t2 : prevRef = " + prevRef);
System.out.println("t2 : change 'b' -> 'a': " +
ref_String.compareAndSet(prevRef, "a"));
},"t2").start();
}
}
|
输出:
1
2
3
4
5
6
| main : prevRef = a
t1 : prevRef = a
t1 : change 'a' -> 'b': true
t2 : prevRef = b
t2 : change 'b' -> 'a': true
main : change 'a' -> 'c': true
|
我们可以看到,线程 1 在 CAS 前已经被线程 2 修改过了,但是这个过程对于线程 1 是不可知的。如果我们希望将其改成线程 1 可以感知到临界区被修改过,我们大致有两种方案:
- 关心修改次数,添加版本号:
AtomicStampedReference
- 关心是否修改过,添加标记:
AtomicMarkableReference
AtomicStampedReference
所谓版本号,其实就是在原来的基础上引入一个整数 stamp 来记录保护的对象被修改的情况(一般是次数),每修改一次,stamp 就会更新。在下面节选的源码中,int stamp 和 T reference 被放在一个 Pair<T> 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
public AtomicStampedReference(V initialRef, int initialStamp) {
pair = Pair.of(initialRef, initialStamp);
}
public V getReference() { return pair.reference; }
public int getStamp() { return pair.stamp; }
public boolean compareAndSet(V expectedReference, // 原来的引用
V newReference, // 更新后的引用
int expectedStamp, // 原来的版本号
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}
}
|
同样的例子,在使用 AtomicStampedReference 后的结果如下图所示:
sequenceDiagram
participant t1 as 线程1(CPU 0)
participant obj as AtomicStampedReference
participant t2 as 线程2(CPU 1)
note over obj : "a" | stamp = 0
obj ->> t1 : get()
note over t1 : prev = "a" | stamp = 0
t2 -->> obj : ⚠️ CAS("a", "b", 0, 0+1) ✅
note over obj : "b" | stamp = 1
t2 -->> obj : ⚠️ CAS("b", "a", 1, 1+1) ✅
note over obj : "a" | stamp = 2
t1 ->> obj : CAS("a", "c", 0, stamp+1) ❌
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public class AtomicStampedReference_of_String {
static AtomicStampedReference<String> ref_String =
new AtomicStampedReference<>("a",0);
public static void main(String[] args) {
String prevRef = ref_String.getReference();
int preStamp = ref_String.getStamp();
System.out.println("main : stamp = " + preStamp);
otherThreadsWorking();
Thread.sleep(1000);
System.out.println("main : change 'a' -> 'c': " +
ref_String.compareAndSet(prevRef, "c", preStamp, preStamp+1));
}
static void otherThreadsWorking() {
new Thread(() -> {
int preStamp = ref_String.getStamp();
System.out.println("t1 : stamp = " + preStamp);
System.out.println("t1 : change 'a' -> 'b': " +
ref_String.compareAndSet("a", "b", preStamp, preStamp+1));
},"t1").start();
Thread.sleep(500);
new Thread(() -> {
int preStamp = ref_String.getStamp();
System.out.println("t2 : stamp = " + preStamp);
System.out.println("t2 : change 'b' -> 'a': " +
ref_String.compareAndSet("b", "a", preStamp, preStamp+1));
},"t2").start();
}
}
|
输出:
1
2
3
4
5
6
| main : stamp = 0
t1 : stamp = 0
t1 : change 'a' -> 'b': true
t2 : stamp = 1
t2 : change 'b' -> 'a': true
main : change 'a' -> 'c': false
|
AtomicMarkableReference
前面我们通过 AtomicStampedReference 给原子引用引入了版本号 stamp,可以追踪原子引用整体的变化情况,如 "a" -> "b" -> "a" -> "c"。通过 AtomicStampedReference 我们可以知道,引用变量被更改的次数。
但是有时候,我们不关系引用变量被更改的次数,只是单纯引用关心变量是否被更改 (boolean),所以就有了 AtomicMarkableReference。
个人理解:
AtomicMarkableReference 是 AtomicStampedReference 的简化版本,只是将 int stamp 替换成 boolean mark。
我们引入一个布尔值 mark 来记录保护的对象是否被修改,每修改一次,mark 就会更新。在下面节选的源码中,boolean mark 和 T reference 被放在一个 Pair<T> 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| public class AtomicMarkableReference<V> {
private static class Pair<T> {
final T reference;
final boolean mark;
private Pair(T reference, boolean mark) {
this.reference = reference;
this.mark = mark;
}
static <T> Pair<T> of(T reference, boolean mark) {
return new Pair<T>(reference, mark);
}
}
private volatile Pair<V> pair;
public AtomicMarkableReference(V initialRef, boolean initialMark) {
pair = Pair.of(initialRef, initialMark);
}
public V getReference() { return pair.reference; }
public boolean isMarked() { return pair.mark; }
public V get(boolean[] markHolder) {
Pair<V> pair = this.pair;
markHolder[0] = pair.mark;
return pair.reference;
}
public boolean compareAndSet(V expectedReference, // 更新前的引用
V newReference, // 更新后的引用
boolean expectedMark, // 更新前的标记
boolean newMark) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedMark == current.mark &&
((newReference == current.reference &&
newMark == current.mark) ||
casPair(current, Pair.of(newReference, newMark)));
}
}
|
同样的例子,在使用 AtomicMarkableReference 后的结果如下图所示:
sequenceDiagram
participant t1 as 线程1(CPU 0)
participant obj as AtomicMarkableReference
participant t2 as 线程2(CPU 1)
note over obj : "a" | mark = false
obj ->> t1 : get()
note over t1 : prev = "a" | mark = false
t2 -->> obj : ⚠️ CAS("a", "a", false, true) ✅
note over obj : "a" | mark = true
t1 ->> obj : CAS("a", "c", false, true) ❌
4 原子数组
上一节我们介绍了原子引用 AtomicReference,它保护的是多个线程对一个对象整体的引用进行修改时的线程安全性,即引用对象整体的地址。
那如果我们想要修改引用对象内部的变量,如数组中的元素,我们引入原子数组对此进行实现。常见的原子数组有:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray 等
首先我们来回顾一下一般对象与数组对象的结构:
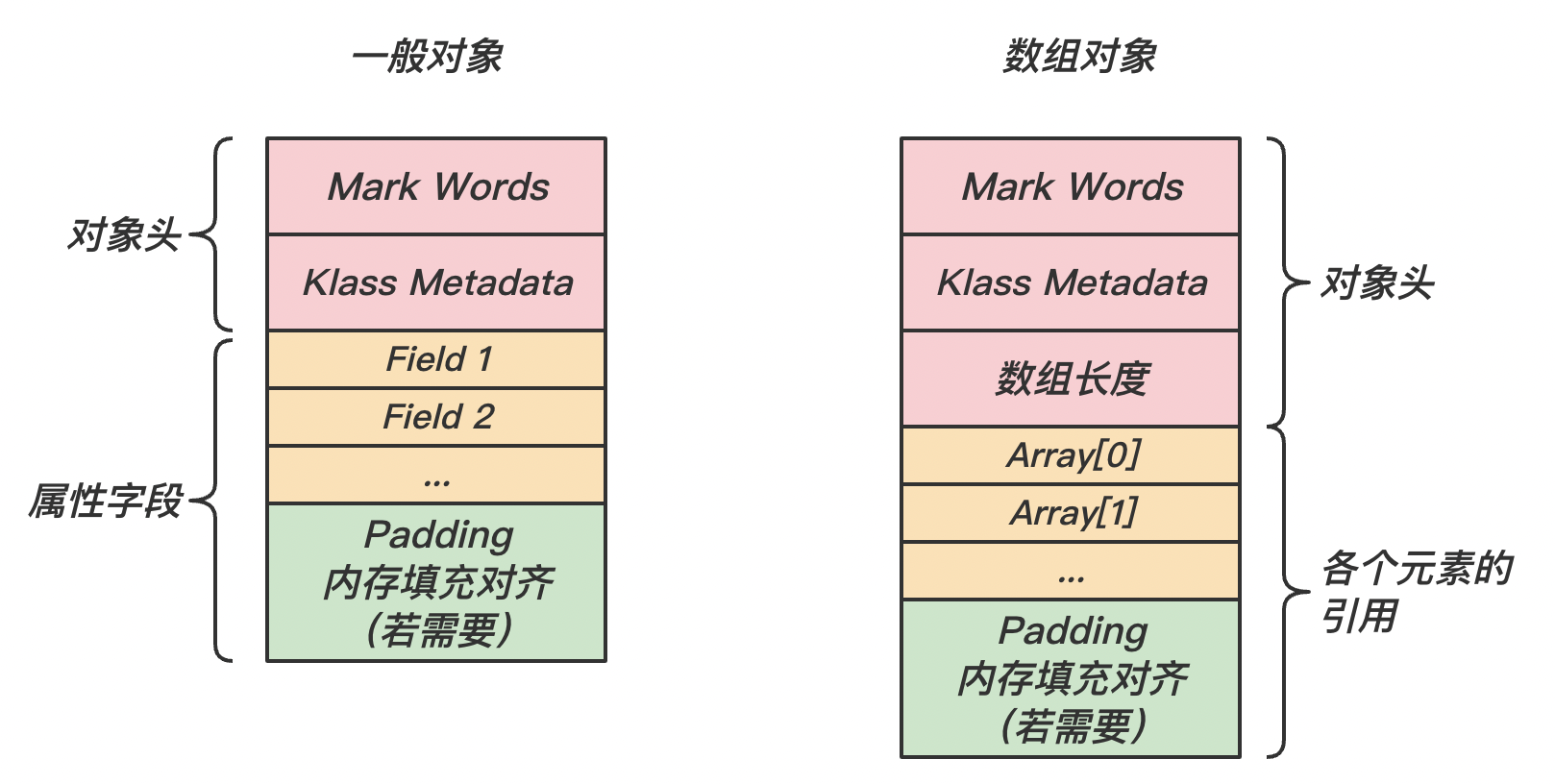
从上图可以看出,【字段】与【对象头】之间的偏移量是固定的,只要知道字段的相对偏移量和对象起始地址,我们就能获取此字段的绝对内存地址:
1
| fieldAddress = objectAddress + fieldOffset
|
根据此绝对内存地址,我们就能忽略访问修饰符的限制而可直接读取/修改此字段的值或引用。
了解了这一点,我们就可以开始分析原子数组的源码了。以 AtomicIntegerArray 为例:
注意 ⚠️
重点分析 base,shift 以及 byteOffset 的作用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| public class AtomicIntegerArray implements java.io.Serializable {
private static final long serialVersionUID = 2862133569453604235L;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final int base = unsafe.arrayBaseOffset(int[].class);
private static final int shift;
private final int[] array;
static {
int scale = unsafe.arrayIndexScale(int[].class);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
shift = 31 - Integer.numberOfLeadingZeros(scale);
}
private long checkedByteOffset(int i) {
if (i < 0 || i >= array.length)
throw new IndexOutOfBoundsException("index " + i);
return byteOffset(i);
}
private static long byteOffset(int i) {
return ((long) i << shift) + base;
}
public final int get(int i) {
return getRaw(checkedByteOffset(i));
}
private int getRaw(long offset) {
return unsafe.getIntVolatile(array, offset);
}
public final boolean compareAndSet(int i, int expect, int update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}
...
}
|
AtomicLongArray,AtomicReferenceArray 与 AtomicIntegerArray 实现基本一致,只是数组对象分别为 long[] 和 Object[] 类型。
5 原子累加器
LongAdder
6 Unsafe
注意 ⚠️
这里只介绍 Unsafe 类中与 CAS 有关的部分,其他部分以后会对于整个 Unsafe 类另做研究。
我们在之前的章节:AtomicInteger 或线程阻塞的 Paker 对象的源码中都看到了一个非常底层的对象 Unsafe 。Unsafe 对象提供了非常底层的,操作内存、线程的方法。
解释
之所以叫 Unsafe,是因为这个类主要提供一些用于执行低级别、不安全操作的方法,如直接访问系统内存资源、自主管理内存资源等,这些方法在提升 Java 运行效率、增强 Java 语言底层资源操作能力方面起到了很大的作用。但由于 Unsafe 类使 Java 语言拥有了类似 C 语言指针一样操作内存空间的能力,这无疑也增加了程序发生相关指针问题的风险。在程序中过度、不正确使用 Unsafe 类会使得程序出错的概率变大,使得 Java 这种安全的语言变得不再“安全”,因此对 Unsafe 的使用一定要慎重。

我们在这里只考虑与 CAS 操作相关的部分知识及源码。
部分源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public final class Unsafe {
private static final Unsafe theUnsafe = new Unsafe();
private Unsafe() {}
@CallerSensitive
public static Unsafe getUnsafe() {
Class<?> caller = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(caller.getClassLoader()))
throw new SecurityException("Unsafe");
return theUnsafe;
}
public final native boolean compareAndSwapObject(Object o, long offset,
Object expected,
Object x);
}
|
我们编写一个小例子,来简单介绍 Unsafe 的用法:
1
2
3
4
5
6
7
8
9
| class Teacher {
volatile int ID;
volatile String name;
@Override
public String toString() {
return "Teacher{" + "ID=" + ID + ", name='" + name + '\'' + '}';
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class demo {
public static void main(String[] args) throws InterruptedException, NoSuchFieldException, IllegalAccessException {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe unsafe = (Unsafe) theUnsafe.get(null);
Teacher teacher = new Teacher();
long IDOffset = unsafe.objectFieldOffset(Teacher.class.getDeclaredField("ID"));
long nameOffset = unsafe.objectFieldOffset(Teacher.class.getDeclaredField("name"));
unsafe.compareAndSwapInt(teacher, IDOffset, 0, 1);
unsafe.compareAndSwapObject(teacher, nameOffset, null, "Marc");
System.out.println(teacher);
}
}
|
输出:
1
| Teacher{ID=1, name='Marc'}
|
手动实现 MyAtomicInteger
UnsafeAccessor:将获取 Unsafe 对象封装成一个类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class UnsafeAccessor {
private static final Unsafe unsafe;
static {
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
unsafe = (Unsafe) theUnsafe.get(null);
} catch (IllegalAccessException | NoSuchFieldException e){
throw new Error(e);
}
}
public static Unsafe getUnsafe() {return unsafe;}
}
|
MyAtomicInteger:自己实现的原子整数类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import sun.misc.Unsafe;
public class MyAtomicInteger {
private volatile int value;
private static final long valueOffset;
static final Unsafe UNSAFE;
static {
UNSAFE = UnsafeAccessor.getUnsafe();
try {
valueOffset = UNSAFE.objectFieldOffset(MyAtomicInteger.class.getDeclaredField("value"));
} catch (NoSuchFieldException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
public MyAtomicInteger(int value) {
this.value = value;
}
public int getValue() {return value;}
public void increment(int num) {
int prev, next;
do {
prev = this.value;
next = prev + num;
} while (!UNSAFE.compareAndSwapInt(this, valueOffset, prev, next));
}
public void decrement(int num) {
int prev, next;
do {
prev = this.value;
next = prev - num;
} while (!UNSAFE.compareAndSwapInt(this, valueOffset, prev, next));
}
}
|
Account:业务类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class Account {
MyAtomicInteger balance;
String name;
public Account(MyAtomicInteger balance, String name) {
this.balance = balance;
this.name = name;
}
public int getBalance() { return balance.getValue(); }
public void depot(int amount) {
balance.increment(amount);
}
public void retrait(int amount) {
balance.decrement(amount);
}
@Override
public String toString() {
return "Account{" + "balance=" +balance.getValue()+ ", name='" +name+ '\'' + '}';
}
}
|
测试
1
2
3
4
5
6
7
8
9
10
| @Test
public void testMyAtomicInteger() {
Account account_1 = new Account(new MyAtomicInteger(10000), "Marc");
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
account_1.retrait(10);
}).start();
}
System.out.println(account_1);
}
|
输出
1
| Account{balance=0, name='Marc'}
|